
Не рекомендуется использовать содержание данной статьи для освоения новой функциональности.
Полное описание новой функциональности будет приведено в документации к соответствующей версии.
Полный список изменений в новой версии приводится в файле v8Update.htm.
Многие наши клиенты используют в своём бизнесе, помимо продуктов 1С, и другие информационные системы от других производителей. Вполне естественным желанием таких клиентов является обеспечить эффективное взаимодействие этих систем.
Примеры сценариев интеграции:
- Офис отправляет в магазины и на сайт изменения в прайс-листе. Приложения, обслуживающие офис, сайт и магазины, могут быть как от 1С, так и от других производителей.
- Накладные отправляются из офиса в магазины автоматически по мере утверждения. В магазине накладные доступны пользователю для работы.
Консолидированная по магазинам информация по остаткам товаров отправляется из офиса в магазины автоматически по расписанию или по требованию. Эта же информация отправляется из магазинов в офис для консолидации в ответ на запрос из офиса остатков автоматически при получении запроса.
Видео:Интеграционные шиныСкачать

Продукт «Интеграционная шина»
Для организации взаимодействия систем предлагается следующая последовательность:
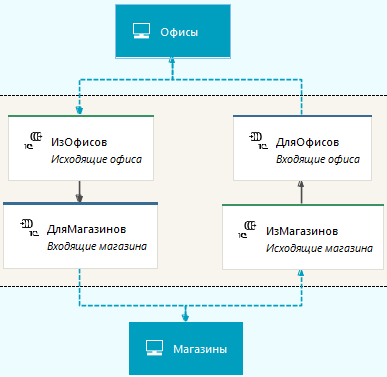
- Разработчик описывает интеграцию систем в специализированном редакторе, используя простую графическую нотацию.
- Маршрут движения сообщений представляется направленным графом, который показывает, как сообщения передаются от источников к назначениям.
- При необходимости можно определить сложный алгоритм маршрутизации сообщений или трансформировать сообщение при помощи процедуры на встроенном языке.
- Источником сообщения может быть файл, результат HTTP запроса, внешний брокер сообщений или подключенная к «Интеграционной шине» внешняя система (такие системы называются участниками взаимодействия).
- Полученное описание сохраняется в специальном объекте Процесс интеграции.
- Определяются параметры Процесса интеграции, значения которых будут определены во время исполнения (пути, адреса сервисов и пр.).
- Созданные разработчиком Процессы интеграции разворачиваются на сервере «Интеграционной шины».
- Администратору сервера доступен графический интерфейс управления «Интеграционной шиной», в котором:
- Задаются значения дополнительным параметрам Процесса интеграции
- Определяются правила подключения Участников взаимодействия к серверу «Интеграционной шины» и способ их участия в процессах интеграции
- Запускаются Процессы интеграции и начинают доставлять сообщения
- Останавливаются Процессы интеграции
- Доступны данные мониторинга работы Процессов интеграции: количество обработанных сообщений, ошибок и пр.
При создании Процесса интеграции разработчик не должен знать точное число систем-участников интеграции. Вместо этого он оперирует понятием группа участников, которое объединяет произвольное количество участников, взаимодействующих с «Интеграционной шиной» единообразно. Во время исполнения администратор определяет, к каким группам относится конкретная система-участник, и для этого участника динамически выделяются необходимые ресурсы.
Видео:Плюсы и минусы сервисной шины данных I Enterprise service bus (ESB) I kt.teamСкачать

Подключение 1С:Предприятия к «Интеграционной шине»
Для поддержки асинхронного обмена сообщениями в платформе 1С:Предприятие версии 8.3.17 добавлен механизм сервисов интеграции. Обмен сообщениями происходит по каналам, организованным на сервере. Канал – это однонаправленный поток сообщений от отправителя к получателю. Сообщения в канал помещаются последовательно отправителем и последовательно доставляются получателю. Сообщения разных каналов обрабатываются и доставляются параллельно. Сообщение доставляется в шину только в том случае, если зафиксирована транзакция, в которой это сообщение отправлено.
- Сообщения, отправленные в один канал в определенной последовательности, будут получены в той же последовательности.
- Любые два сообщения, полученные из разных каналов в определенной последовательности, не обязательно будут обработаны в этой же последовательности, так как обработка сообщений из разных каналов может идти с разной скоростью.
Механизм сервисов интеграции в 1С:Предприятие не является альтернативной механизмам планов обмена, так как отвечает только за транспортировку сообщений, а не за формирование исходящих и интерпретацию входящих сообщений.
Взаимодействие с «Интеграционной шиной» выполняется с гарантированной доставкой сообщения, что означает:
- Отправляемое в «Интеграционную шину» сообщение сохраняется в информационной базе до тех пор, пока от «Интеграционной шины» не будет получено подтверждение того, что сообщение им получено.
- Система 1С:Предприятие будет выполнять попытки доставить сообщения «Интеграционной шине», пока не будет получено подтверждение получения сообщения или сообщение не устареет (у сообщения может быть установлен «срок годности»).
- При получении сообщения от «Интеграционной шины» это сообщение сохраняется в информационной базе, и только после этого «Интеграционной шине» подтверждается получение сообщения.
Видео:Интеграционная шина - обмен данными между подразделениями предприятияСкачать

Пример сценария интеграции
Офис отправляет в магазины и на сайт изменения в прайс-листе.
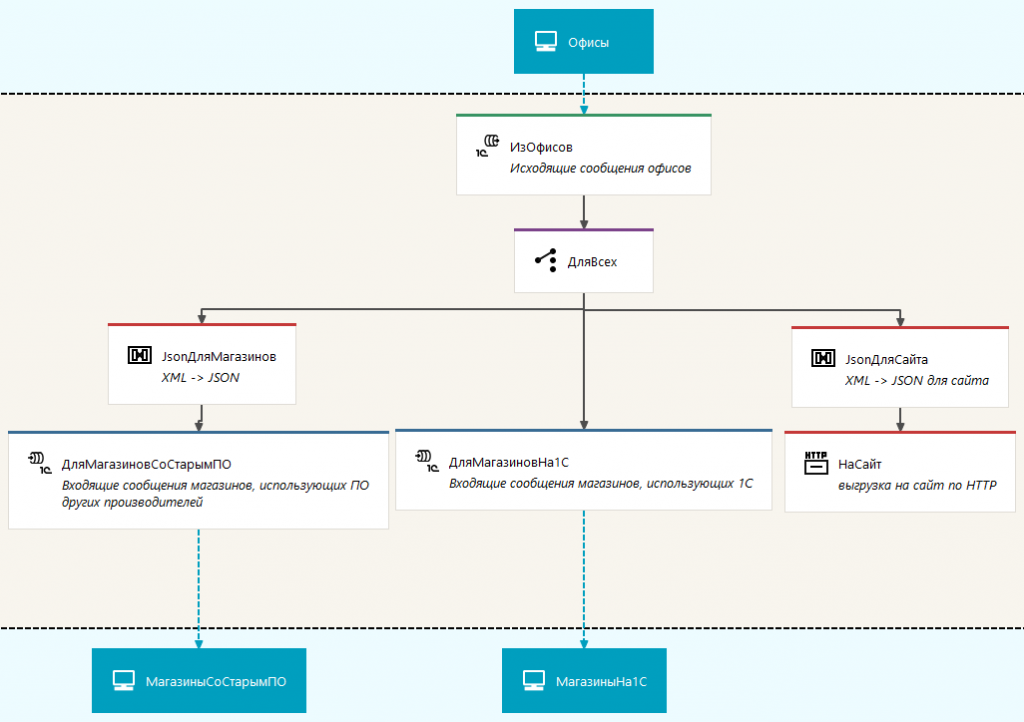
Схема содержит три группы участников: «Офисы», «МагазиныСоСтарымПО» и «МагазиныНа1С». В группе «МагазиныНа1С» объединены участники, которые используют для автоматизации системы на платформе 1С:Предприятие. В группе «МагазиныСоСтарымПО» собраны участники, которые используют ПО других производителей.
В момент изменения прайс-листа в офисе формируется сообщение, содержащее актуальный прайс-лист в формате EnterpriseData. Это сообщение отправляется в канал «ИзОфисов».
В узле «ДляВсех» все сообщения из канала «ИзОфисов» маршрутизируются по трем направлениям:
- Для передачи магазинам, использующим старое ПО, в формате JSON. Преобразование из исходного XML происходит в узле вида «Транслятор» с именем «JsonДляМагазинов». Полученный JSON отправляется в канал «ДляМагазиновСоСтарымПО».
- Для передачи магазинам, использующим ПО 1С, сообщение в исходном виде отправляется в канал «ДляМагазиновНа1С».
- Для публикации на сайте. Преобразование из исходного XML происходит в узле вида «Транслятор» с именем «JsonДляСайта». Полученный JSON отправляется на сайт HTTP запросом в узле «НаСайт».
При настройке такого процесса интеграции разработчику совершенно не важно, сколько магазинов каждого вида будет участвовать в интеграции.
Видео:Интеграционная шина предприятия. Правило импорта.Скачать

Преимущества нашей «Интеграционной шины»
После знакомства с «Интеграционной шиной» может возникнуть естественный вопрос: рынок ПО класса ESB достаточно обширен, на нем представлено немало достойных продуктов, в том числе и бесплатных; зачем же фирме «1С» делать ещё один продукт, не изобретаем ли мы велосипед?
Конечно, перед тем, как принять решение разрабатывать «Интеграционную шину», мы задались тем же вопросом. И ответили себе на него так — да, делать продукт сто́ит, потому что:
- Мы постарались сделать наш продукт максимально простым и удобным в использовании.
- Мы сделали интеграцию нашего продукта с приложениями 1С максимально гладкой.
- «Интеграционная шина» от 1С легка в освоении для разработчиков 1С и позволит клиентам во многих случаях для настройки процессов интеграции обходиться усилиями существующих ИТ-специалистов (партнера 1С и/или своего ИТ-отдела, обслуживающего клиента).
- Наш продукт будет органично вписываться в экосистему 1С и позволит решить нашим клиентам задачи своего бизнеса наиболее эффективным способом.
Мы планируем развивать продукт, в частности, увеличивать количество способов взаимодействия с внешними системами, улучшать средства мониторинга, ввести возможность добавлять сервисы интеграции через расширения, устанавливать связь сервисов интеграции и планов обмена.
Мы планируем этап бета-тестирования «Интеграционной шины» и будем рады помощи партнеров и клиентов. Чтобы участвовать в бета-тестировании продукта нажмите зелёную кнопку «Пробовать» в начале статьи.
Читайте также: Дата производства в маркировке шины
Видео:Интеграция систем на примере шины ESB · Евгений Путилин · ЛАФ #системныйаналитикСкачать

События, шины и интеграция данных в непростом мире микросервисов

Валентин Гогичашвили объясняет микросервисы. Перед вами расшифровка доклада с Highload++.
Добрый день, я Валентин Гогичашвили. Все слайды я сделал латиницей, надеюсь не будет проблем. Я из Zalando.
Что такое Zalando? Наверное, вы знаете Lamoda, Zalando был папой Lamoda своё время. Чтобы понять, что такое Zalando, нужно представить Lamoda и увеличить в несколько раз.
Zalando – это магазин шмоток, мы начали продавать обувь, очень хорошую между прочим. Начали расширяться всё больше и больше. Снаружи сайт выглядит очень просто. За 6 лет что я работаю в Zalando и за 8 лет существования — эта компания была одной из самых быстрорастущих в Европе в какое-то время. Шесть лет назад, когда я пришел в Zalando, она росла где-то 100%.
Когда я начинал 6 лет назад, это был маленький стартап, я пришёл довольно поздно, там уже было 40 человек. Мы начинали в Берлине, за эти 6 лет мы расширили Zalando Technology на много городов, включая Хельсинки и Дублин. В Дублине сидят data-science’ы, в Хельсинки сидят mobile developer’ы.
Zalando Technology растёт. На данный момент мы нанимаем в районе 50 человек в месяц, это страшное дело. Почему? Потому что мы хотим построить самую крутую fashion-платформу в мире. Очень амбициозно, посмотрим, что получится.
Хочу немножко вернуться в историю и показать вам старый мир, в котором вы, скорее всего, в какой-то момент вашей карьеры определенно были.
Zalando начинался как маленький сервис у которого было 3 уровня: web applicaton, backend и база данных. Мы использовали Magento. К тому моменту, когда меня позвали в Zalando, мы были самыми большими пользователями Magento в мире. У нас были огромные головные боли с MySQL.
Мы начали проект REBOOT. Я и пришел на этот проект 6 лет назад.
Что мы сделали?
Мы переписали все на Java, потому что мы знали Java. Мы поставили везде PostgreSQL, потому что я знал PostgreSQL. Ну и Python – это дело техники. Практически любой нормальный человек меня поддержит, что Python для tooling’a — это единственное правильное решение (люди из мира Perl, не убивайте меня). Python это хорошая шутка для написания tooling.
У нас начала развиваться такая схема:
У нас была система macro services. Java Backend, PostgreSQL storage c PostgreSQL шардингом. Я два года назад на этой же конференции рассказывал о том, как мы делаем PostgreSQL-шардинги, как мы управляем схемами, как мы выкатываем версии без downtime, было очень интересно.
Как я сказал, Java мы все знали. SOAP использовался для объединения macro-сервисов друг с другом. PostgreSQL давал нам возможность иметь очень чистые данные. У нас была схема, чистые данные, транзакции и хранимые процедуры, котором мы научили всех java-developer’ов или тех, кто еще остались из PHP-мира, которых мы научили Java и хранимым процедурам.
Один хинт: если вы находитесь в режиме меньше 15 миллионов пользователей в месяц, то вы можете использовать систему Java SProc Wrapper для автоматического шардирования PostgreSQL из Java. Очень интересная штука, которая PostgreSQL в RSP-систему, по существу.
Всё было хорошо, мы написали и переписали всё. Мы сперва купили систему управления нашими складами, а потом всё переписали. Потому что мы должны были двигаться намного быстрее чем те люди, у которых мы купили систему могли это сделать.
Всё прекрасно работало пока не началась проблема с кадрами. Наш прекрасный мир начал рушиться на глазах. Система стандартизации, ее уровень, который мы ввели на уровне Java, SOAP начал крошиться. Люди начали жаловаться и уходить или просто не приходить.
Мы им говорили: вы должны писать на Java, если вы уйдете, что мы будем делать? Если вы напишите что-то на Haskell или на Clojure и уйдете что мы будем делать? А они нам отвечали fuck you.
Мы решили подойти к делу серьезно. Мы решили перестроить не только архитектуру, но и всю организацию. Мы начали процесс перестройки организации, которая не видела немецкая индустрия, в которой мы сказали, что мы разрушаем полностью всё, что у нас было. Это была организация в которой было в районе 900 человек, мы разрушаем иерархическую структуру в том виде в которой она была. Мы объявляем Radical Agility.
Видео:Интеграционная шина данных для ВУЗовСкачать

Что это значит?
Мы объявляем, что у нас есть команды, которые автономны, которые двигаются вперед осмысленно. Конечно же мы хотим, чтобы люди, которые занимались делом, они делали это дело с мастерством.
Они могут выбрать своё собственное технологический стэк. Если команда решила, что они будет писать на Haskell или Clojure, то пусть так и будет. Но за это надо платить. Команды должны поддерживать сервисы, которые они написали сами, просыпаться ночью сами. Включая выбор персистент стэка. Мы вам научили PostgreSQL, если вы хотите выбрать MongoDB, а нет стоп, MongoDB у нас заблокирован. У нас есть радар технологий в котором мы проводим помесячные опросы и технологии, которые считаем опасными, ставим на красный сектор. Это означает, что команда могут выбирать эти технологии, но они пенять полностью на себя, если что-то пойдет не так.
Мы сказали, что команды будут изолированы своими AWS-аккаунтами. До этого мы были в своих собственных дата центрах, выбрав AWS, мы пошли на сделку с дьяволом. Мы сказали, мы знаем, что это будет стоить дороже, но мы будем двигаться быстрее. У нас не будет ситуаций как до этого, в собственных дата центрах: для того, чтобы заказать один жесткий диск, требовалось 6 недель. Это было невыносимо и невозможно. Мы не могли двигаться вперед.
Очень многие люди считают, что автономия — это анархия. Автономия — это не анархия. С автономией приходит очень много ответственности, особенно для Zalando, которая publicly traded company. Мы на бирже и как в любую publicly traded company к нам приходят аудиторы и они проверяют, как работают наши системы. Мы должны были создать какую-то структуру, которая позволит нашим developer’ам работать с AWS, но всё же оставаться способными отвечать на вопросы аудиторов уровня: «Почему у вас это IP-адрес в публичном доступе без идентификаций?»
Читайте также: Шина для навеса кухонь
Получилась вот такая система:
Мы хотели сделать её максимально простой, она действительно простая. Но все ругаются, когда видят её.
Если вы уходите в AWS, напоминание вам, с этой быстротой и с открытостью, и если вы выбираете идею с микросервисами или публичными сервисами, то за это может быть придётся платить. В том числе если вы хотите сделать систему, которая безопасна, которая отвечает на вопросы, которые могут задавать наши аудиторы.
Конечно же мы сказали, что для того чтобы поддерживать разнородный стэк технологий мы поднимаем уровень стандартизации с Java и PostgreSQL на более высокий уровень. Мы поднимаем уровень стандартизации на уровень REST APIs.
Что это значит? Я отмечал это на предыдущем докладе о том, что нам нужна система описания API. Описание системы того как микросервисы общаются друг с другом. Нам нужен порядок. На каком-то уровне нам нужно стандартизироваться. Мы объявили о том, что у нас будет система API first. И что каждый сервис перед тем как его начнут писать, команда должна прийти в API гильдию и уговорить их принять API в состав утвержденных API. Мы написали REST API guidelines, очень интересные. На них даже ссылались в некоторых ресурсах. API first библиотеки, которые позволяют использовать Swagger (OpenAPI) в качестве руторов для сервера. Например, connection — это рутор для flask’a в Python, а play-swagger — это рутор для play-системы в Scala. Для Clojure есть такой же рутор, это очень удобно. Вы пишите сперва Swagger файл, описываете то, чего вы хотите добиться от своего микросервиса, а потом просто указываете, какие функции в вашей системе должны исполнять те или иные операции в API.
Но проблема с микросервисами. Я хочу несколько раз повторить эту фразу. Микросервисы — это ответ на организационные проблемы, это не технический ответ. Я не буду советовать микросервисы никому, кто маленький. Я не буду советовать микросервисы тем, у кого нет проблем с разношерстной технологической базой, кому не нужно писать один сервис на Scala, другой сервис на Python или Haskell. Количество проблем с микросервисами довольно высокое. Этот барьер. Для того, чтобы его преодолеть, нужно довольно много боли испытать перед этим, как сделали это мы.
Одна из самых больших проблем с миркосервисами: микросервисы по своей дефиниции закрывают доступ к системе персистирования данных. Базы спрятаны внутри микросервиса.
Таким образом классический extract transform load process не работает.
Давайте сделаем один шаг назад и вспомним, как работаем в классическом мире. Что у нас есть? У нас есть классический мир, у нас есть developer’ы, junior developer’ы, senior developer’ы, DBA и Business Intelligence.
Как это работает?
В простом случае у нас бизнес логика, база, ETL процесс достаёт прямо из базы наши данные и засовывает в Date Warehouse (DWH).
В большем масштабе у нас есть много сервисов, много баз и один процесс, который пишется, скорее всего, ручками. Вытаскиваются данные из этих баз и кладутся в специальную базу для бизнес-аналитиков. Она очень хорошо структурирована, бизнес аналитики понимают, что они делают.
Конечно это всё — не без проблем. Это всё очень трудно автоматизировать. В мире микросервисов у нас всё не так.
Когда мы объявили о микросервисах, когда мы объявили о Radical Agility, когда мы объявили об этих всех прекрасных нововведениях для developer’ов, бизнес-аналитики были очень недовольны.
Как собирать данные из огромного количества микросервисах?
Речь идет не о десятках, а о сотнях или даже тысячах. Потом приходит Валентин на коне и говорит: мы всё будет писать в поток, в queue. Потом архитекторы говорят: почему queue? Кто-то будет использовать Kafka, кто-то будет использовать Rabbit, как мы будет это всё интегрировать? Наши security-officer’ы сказали: никогда в жизни, мы не позволим. Наши бизнес-аналитики сказали: если там не будет схемы, мы повесимся и не сможем понять, что течёт, это же будет просто сточная канава, а не система транспорта данных.
Мы сели и начали совещаться и решать, что же делать. Наши основные цели: простота использования нашей системы, хотим, чтобы у нас не было single point of failure, не было такого монстра, который если он упадёт, то всё упадёт. Должна быть безопасная система, и эта система должна удовлетворять потребностям бизнес-аналитики, система должна удовлетворять наших data-science’ов. Она должна в хорошем случае дать возможность другим сервисам использовать эти данные, которые текут через шину.
Из Event Bus мы сможем вытаскивать Business Intelligence или в какие-то Data heavy services. DDDM это любимое понятие в последнее время. Это data driven decisions making system. Любой менеджер будет в восторге от такого слова. Machine learning and DDDM.
Что мы придумали?
Nakadi. Вы наверно поняли, что у меня фамилия довольно грузинская. Nakadi по-грузински значит поток. Например, горный поток.
Мы начали делать такой поток. Основные принципы, которые мы туда вложили, немножко повторюсь.
Мы сказали, что у нас будет стандартный HTTP API. По возможности — restful. Мы сделаем централизованную или по возможности не очень централизованную event type registry. Мы введём разные классы event types. Например, на данный момент у нас поддерживается два класса. Это data capture и business events. То есть если у нас меняются сущности, то мы можем event capture записывать с всей необходимой метаинформацией. Если у нас просто информация о том, что в бизнес-процессе что-то произошло, то это обычно намного более простой случай, и мы можем писать более простой event. Но всё равно бизнес-аналитики требуют, чтобы у нас была организована структура, которую можно будет автоматически парсить.
Имея огромный опыт работы с PostgreSQL и со схемами, мы знаем, что без поддержки версионирования схем ничего не будет работать. То есть если мы скатимся до уровня, где программисты должны будут описывать order created, затем order created 1,2,3, мы будем, по существу, делать систему похожую на Microsoft Windows, и это будет очень трудно, особенно для того чтобы понимать, как развиваться сущность, как версионируется сущность. Очень важно, чтобы этот интерфейс позволял стримить данные, чтобы можно было реагировать как можно быстрее на приход сообщений и оповещать всех желающих о приходе сообщения.
Читайте также: Шины hankook winter i pike w419 175 65 r14 86t
Мы не хотели изобретать велосипед. Наша цель — сделать максимально минимальную систему, которая будет использовать существующие системы. Поэтому на данный момент мы взяли Kafk’у, как underline систему и PostgreSQL для хранения метаданных и схемы.
Nakadi Cluster — это то, что у нас есть. Существует в виде open source проекта. В данный момент он валидирует схему, которую регистрировали до этого. Он умеет записывать дополнительную информацию в метаполя для event’a. Например, время прихода или если клиент не создал уникальные id для event’a, то и уникальные id туда можно запихнуть.
Также мы посчитали, что нужно взять на себя управление offset’ами. Те, кто знает, как работает Kafka. Кто-нибудь знает? Хорошо, но не большинство. Kafka – классическая pub/sub-система, в которой продюсер записывает данные последовательно, а клиент не хранит, как в классических message-системах.
Для клиента не создаются отельные копии message, единственное, что нужно клиенту, — это offset. То есть сдвиг в этом бесконечном потоке. Можете представить, что Kafka — это такой бесконечный поток данных, в котором пронумерована каждая сточка. Если ваш клиент хочет забрать данные, он говорит: читай с позиции X. Kafka даст ему эти данные из позиции X. Таким образом гарантируется упорядоченность данных, таким образом гарантируется что на сервере не надо хранить очень много информации, как обычно делается в классических message-системах, которые позволяют комитить часть прочитанных event’ов. В данной ситуации у нас есть проблема в том нельзя закомитить кусок прочитанного блока. Сейчас пошёл offtext, про Kafk’y не хотел говорить, извините.
High level interface делает чтение из kafk’и очень простым для клиентов. Клиенты не должны обмениваться информацией, кто из какого раздела читает, какие offset’ы они хранят. Просто приходит клиент и получает то, что нужно из системы. Мы решили по пути минимального сопротивления. Zookeeper уже есть для Kafk’и, какой бы ужасный Zookeeper не был, он у нас уже есть, нас уже нужно его manage’ить и мы используем его для хранения offset’ов и дополнительной информации. PostgreSQL — для метаданных и хранения схем.
Сейчас я хочу рассказать в каком направлении мы движемся.
Мы движемся очень быстро. Поэтому, когда я вернусь в Берлин, какие-то части будут уже сделаны.
На данный момент у нас есть Nakadi Cluster, у нас есть Nakadi UI, который мы начали писать на Elm, чтобы заинтересовать других людей. Elm крутой, люблю его.
Следующим шагом мы хотим иметь возможность управлять несколькими кластерами. Мы уже видели косяки, когда приходит новый продюсер и начинает писать 10 тысяч event’ов в секунду, не предупредив ни о чем.
Наш кластер не успевает масштабироваться. Мы хотим, чтобы у нас были разные кластеры по разным типам данных. Стандартизацию интерфейса мы делали специально так, чтобы не было никакой завязки на Kafk’y.
Мы можем переключиться с Kafk’и на Redis. А с Redis’a на Kinesis. По существу, идея такая, что в зависимости от необходимости сервиса и свойств event’ов, которые они пишут, если кому-то не интересен ordering, упорядоченность, то можно использовать систему, которая не поддерживает ordering и более эффективна, чем Kafka. На данный момент у нас есть возможность абстрагировать это, используя наш интерфейс.
Nakadi Scheme Manager нужно вытаскивать из кластера, потому что он должен быть зашерен. Следующий шаг — такая идея, чтобы у нас схемы детектировались. То есть поднимается микросервис, публицирует свой swagger-файл, публицирует список event’ов в том же формате, что и swagger. Автоматически crawker забирает это всё и избавляет developer’ов от необходимости дополнительно перед deployment’ом inject’ить схему в message bus.
Ну и конечно, topology manager, чтобы можно было каким-то образом рутить продюсером и консюмеров на разные кластеры. Тут рассказывали, что Kafka работает как слон. Нет, не как слон, а как паровоз. В нашей ситуации этот паровоз всё время ломается. Не знаю, кто производил этот паровоз, но для того, чтобы управлять Kafk’ой в AWS, оказалось, что это не так просто.
Мы написали систему Bubuku, очень хорошее название, очень русское.
У меня был большой слайд, на котором было указано что делает Bubuku, но он получился очень большим. Всё можно посмотреть по ссылке.
В прицепе Bubuku имеет цели делать то, что не делают другие с Kafk’ой. Основные идеи что это автоматически reportition, автоматический scaling и возможность пережить попадания молнией, crazy monkeys которые убивают инстансы.
Кстати, у нас систему тестирует Chaos Monkey, и очень даже неплохо всё это работает. Всем рекомендую, если вы пишите микросервисы, всегда думайте, как эта система переживает Chaos Monkey. Это — Netflix-система, которая рандомно убивает ноды или отключает сеть, портит вам систему
Какую бы вы систему ни построили, если вы её не тестируете, то она не будет работать, если что-то поломается.
Заключая свой поверхностный рассказ, хочу сказать: то, о чем я рассказывал, сейчас мы разрабатываем в open source. Почему open source? Мы даже написали, почему Zalando делает open source.
Когда люди пишут в open source, они пишут не для компании, а для себя отчасти. Поэтому мы видим, что качество продуктов лучше, мы видим, что изолируемость продуктов от инфраструктуры лучше. Никто не записывает внутрь zalando.de и не правят ключи, не комитят в Git.
У нас есть принципы о том, как open source’ить. Есть ли у вас вопросы в компании должны ли мы open source’ить или нет? Есть принцип open source first. Перед тем как начать проект, мы думаем, стоит ли его open source’ить. Для того что понять и ответить на этот вопрос, нужно ответить на вопросы:
- Кому это надо?
- Нужно ли это нам?
- Хотим ли мы с этим заниматься, как open source проектом?
- Можем ли мы то что мы будем держать в этом publice tree?
Есть вещи, когда не надо open source:
- Если ваш проект содержит domain knowledge, то что делает компанию вашей компанией, это нельзя open source’ить, конечно.
Это последний слайд, здесь проекты, которые были упомянуты сегодня:
📹 Видео
Интеграционная шина: потребности бизнесаСкачать

Способы интеграции системСкачать

Интеграционная шина предприятия. Структура правила экспортаСкачать

Интеграционная шина данных | 1C ERP интеграция | Связь между системамиСкачать

СПРОСИ ЭКСПЕРТА: Выпуск 1. Чем отличается шина данных от ETL?Скачать

Интеграционная шина предприятия. ЛОЦМАН-1С. Конструкторский составСкачать

Вебинар "InterSystems IRIS как сервисная шина предприятия (Enterprise Service Bus)"Скачать

Сервисная шина и система - кто должен инициировать сообщения? | Андрей ПутинСкачать

Шины - ключевой элемент качественной архитектуры | Андрей ПутинСкачать

Шины VS брокеры сообщений | KT.Team | Андрей ПутинСкачать

Опыт внедрения ESB интеграционной шины в ПАО «Газпром Нефть» Михаил ХаритоновСкачать

PSO - корпоративная интеграционная шина данныхСкачать

Интеграционная шина предприятия. ЛОЦМАН-1С. Технологические процессыСкачать
