

В данной статье (будет состоять из двух частей) хотел бы кратко пройтись по основным технологиям стекирования коммутаторов Cisco. Попробуем разобраться с общей архитектурой передачи пакетов в рамках каждого типа стека, реакцией на отказы, а также с цифрами пропускной способности. В первой части мы рассмотрим технологии StackWise и StackWise Plus. Во второй части — StackWise-160, StackWise-480, FlexStack и FlexStack Plus.
Сейчас функционалом стекирования никого не удивишь. Он есть во многих моделях коммутаторов различных производителей, в том числе и у Cisco. Но так было не всегда. На заре моей карьеры (где-то середина двухтысячных) в области сетевых технологий в портфеле компании Cisco был всего один коммутатор с поддержкой полноценного стека. Это была модель коммутатора Cisco 3750. Псевдо стеки на базе 2950 и 3550 в ту пору уже практически умерли. На тот момент меня, как молодого специалиста, очень удивлял факт того, что вопросу стекирования коммутаторов компанией Cisco уделялось так мало внимания. При этом, например, у коммутаторов 3com (прим. куплен компанией HP), которые в то время были достаточно популярны, стекирование поддерживалось достаточно на большом перечне моделей. Также обстояли дела и у Allied Telesis. Я даже помню, как приверженцы продукции Cisco мне объясняли, что стекирование – это плохо, и в продакшене данную технологию не стоит использовать. Жаль, уже не помню точных формулировок, но речь шла вроде о стабильности работы. Стоит заметить, что в то время основными доводами в пользу стекирование было упрощение управления (во всяком случае, на тот момент мне казалось именно так). Т.е. вместо того, чтобы настраивать отдельно два или более устройства, стек даёт нам возможность получить один большой коммутатор.
Шло время. Многие осознали плюсы стекирования. И сейчас большая часть коммутаторов Cisco поддерживет данную технологию. В настоящее время, говоря о стекировании, стоит разделять стек на уровне доступа (там, где подключаем обычных пользователей) и стек во всех остальных случаях.
В первом случае основной причиной объединения коммутаторов в стек является упрощение администрирования. В какой-то момент времени мне даже стало казаться, что это уже совсем не актуально и является больше маркетинговым моментом. Но не так давно в общении с заказчиком, у которого большой парк автомобилей сетевых устройств, выяснил, что главной причиной объединения коммутаторов в стек на уровне доступа стало именно это.
Во всех остальных случаях, на мой взгляд, основным «за» в пользу стека стала возможность организации относительно недорогой схемы отказоустойчивости в сети (как на уровне ядра сети, так и при подключении серверного оборудования). Стек позволяет нам агрегировать физические каналы, заведённые на разные коммутаторы, в один логический. Это обеспечивает нас не только большей пропускной способностью (за счёт утилизации одновременно нескольких каналов) и отказоустойчивостью (выход из строя одного из коммутаторов стека не приведёт к остановке сети), но и в ряде случаев даёт возможность полностью отказаться от петель. А значит от использования протоколов семейства STP. Т.е. упрощает жизнь, делая топологию сети достаточно простой.
На оборудовании Cisco в зависимости от платформы используются несколько технологий стекирования. Небольшое замечание. Рассматривать будем классические схемы стекирования. Технология VSS останется за кадром.
| Технология | Платформа | Кол-во коммутаторов в стеке | Общая пропускная способность стековой шины | Необходимость стекового комплекта |
|---|---|---|---|---|
| StackWise | 3750, 3750G | 9 | 32 Гбит/с | Нет |
| StackWise Plus | 3750-E, 3750-X | 9 | 64 Гбит/с | Нет |
| StackWise-160 | 3650 | 9 | 160 Гбит/с | Да |
| StackWise-480 | 3850 | 9 | 480 Гбит/с | Нет |
| FlexStack | 2960-S, 2960-SF | 4 | 40 Гбит/с | Да |
| FlexStack Plus | 2960-X, 2960-XR | 8 | 80 Гбит/с | Да |
Предлагаю чуточку подробнее разобраться с цифрами общей пропускной способности стековой шины, а также общей архитектурой передачи пакетов в рамках каждого типа стека. Хотел бы пояснить, что под стековой шиной будем подразумевать внутренние интерфейсы и порты, которые обеспечивают стекирование. Её производительность — это суммарная полезная пропускная способность всех стековых портов. Почему я не говорю про общую производительность стека? Это обусловлено тем, что в большинстве технологий при выполнении коммутации пакетов между внутренними портами одного коммутатора, используется лишь внутренняя логика (коммутационная фабрика, ASICи и пр.). В этом случае пакет не попадает на стековую шину. Стековая шина утилизируется только тогда, когда пакет попадает на порт одного коммутатора, а выходит через порт уже другого коммутатора стека.
Рассмотрим технологию StackWise. Она является самой пожилой среди остальных. Для соединения коммутаторов в стек по технологии StackWise используется специализированный стековый кабель. При этом отдельного стекового модуля нет, стековые порты сразу встроены в коммутатор (по два порта).

Пропускная способность стекового кабеля 16 Гбит/с (в каждую сторону). Так как на каждом коммутаторе два стековых порта, пропускная способность стековой шины должна равняться:
16 Гбит/с * 2 (в каждую сторону) * 2 (количество портов) = 64 Гбит/с
Смотрим в спецификацию, а там 32 Гбит/с. Куда делась половина пропускной способности?
В коммутаторах 3750 (3750v2) и 3750G отсутствует как таковая выделенная внутренняя коммутационная фабрика (используется старая архитектура shared-ring switch fabric). Стековые порты подключаются напрямую к внутренней шине коммутатора, становясь её продолжением. Таким образом, коммутаторы одного стека имеют одну большую шину в виде кольца. Данная шина на логическом уровне представляет собой два пути в виде кольца каждый.
Пропускная способность каждого из них — 16 Гбит/с. Эти пути разнонаправленные: пакеты по ним передаются в противоположные стороны. Так как мы имеем общую шину на весь стек, пакет, попав на порт любого коммутатора стека, обязательно пройдёт не только через все внутренние ASIC’и, но и через всё кольцо стека, даже если исходящий порт находится на том же коммутаторе, что и входящий. Причём пакет будет убран с шины, только когда он пройдёт весь круг и вернётся обратно. Это позволяет ASIC’у, который «захватил» один из путей, узнать о том, что пакет дошёл и путь можно освобождать. Такой алгоритм работы можно называть «удаление отправителем» (в терминах Cisco — Source stripped). Выбор пути, по которому отправить пакет, определяется исходя из доступности каждого из них (используется механизм токенов: тот ASIC, который обладает токеном, передаёт данные).
Давайте рассмотрим это на примере (Рис. 2). В нашем случае пакет, попав на порт коммутатора (1), попадает на ASIC, который в свою очередь выбирает синий путь (2) (допустим, он был свободен в этот момент). Далее пакет по синему пути проходит через все коммутаторы (3), попадая в итоге на тот коммутатор, где находится порт назначения (4). Коммутатор отправляет копию пакета (5) через свой локальный порт. Но сам пакет продолжает своё путешествие по стековому кольцу (6), пока не достигнет ASIC’а, который его изначально отправил (7). Только там он будет удалён со стековой шины.

Таким образом, один и тот же пакет проходит 2 раза через стековые порты коммутатора (сначала через один (3), потом через второй (6) порты). А значит наша общая полезная пропускная способность стековой шины равна 32 Гбит/с (ровно в два раза меньше физической).
А, что будет если один из коммутаторов стека откажет? В этом случае пути замкнутся друг на друга, тем самым образуя одно большое кольцо (Рис. 3). Ровным счётом также поведут себя коммутаторы в случае, если будет отключён один из стековых кабелей.

Стоит отметить ещё два момента. Два пути «крутятся» в разные стороны. Предполагаю, что это сделано для усреднения задержки передачи пакетов внутри стека. Второй момент заключается в том, что для Stackwise пропускная способность стековой шины равна общей производительности стека, в силу того, что все коммутаторы в стеке используют одну общую шину.
Перейдём к технологии StackWise Plus. В коммутаторах 3750E и 3750X была добавлена выделенная коммутационная фабрика (switch fabric). Это позволяет делать локальную коммутацию пакетов без их появления в стековом кольце. Стековые порты заводятся непосредственно на коммутационную фабрику. Теперь за логику работы со стековой шиной отвечает непосредственно коммутационная фабрика. В случае технологии StackWise со стековой шиной работал каждый ASIC отдельно.
В технологии StackWise Plus был использован новый алгоритм обработки пакетов в стеке – «удаление получателем» (в терминах Cisco — Destination stripped, ещё одно наименование Spatial reuse). В данном алгоритме пакет удаляется со стековой шины сразу же, как только он достиг коммутатора, на котором находится исходящий порт (Рис. 4). Теперь для сигнализации о том, что путь можно освобождать используется маленький Ack пакет (8 бит).
Читайте также: Остаток протектора шины nokian
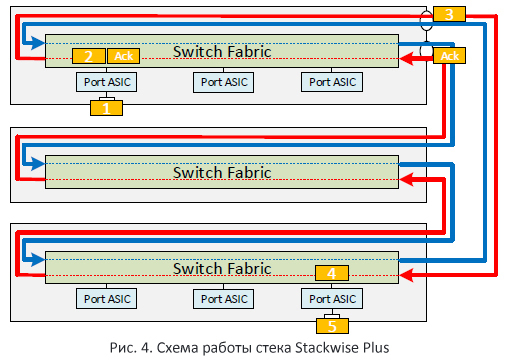
Как и в технологии Stackwise, логически у нас остаётся два пути. Но так как теперь за работу со стековым кольцом отвечает коммутационная фабрика, механизм работы с этими путями усложнился. Как и раньше доступ к тому или иному пути осуществляет с помощью механизма токенов. Получив токен, коммутационная фабрика может передавать пакеты по стековому кольцу. А так как непосредственно пакеты забираются с каждого ASIC’а, за порядок обслуживания каждого ASIC’a отвечает механизм кредитов. Их раздаёт коммутационная фабрика.
Эти новшества позволили увеличить пропускную способность стековой шины до маркетинговых 64 Гбит/с, прировняв полезную пропускную способность к физической. Теперь пакет проходит только один раз через стековый порт коммутатора. Хотел бы обратить внимание, что в обоих технологиях (Stackwise и StackWise Plus) используются одни и те же типы стековых кабелей.
Тут стоит подчеркнуть, что пропускная способность стековой шины не стала равна 64 Гбит/с, она стала стремиться к этой цифре. Почему? Причина в том, что весь трафик broadcast, multicast и unknown unicast продолжает обрабатываться по алгоритму Source stripped. Т.е. эти типы трафика проходят всё кольцо, прежде чем будут удалены со стековой шины. А значит на данные типы трафика расходуется двойная пропускная способность.
В одном стеке допускается использование любых коммутаторов серии 3750. Если в один стек добавить, например, коммутаторы 3750v2 (поддерживают StackWise) и 3750X (StackWise Plus), стек будет работать по технологии StackWise (алгоритм Source stripped). При этом для 3750X коммутация пакетов между локальными портами будет осуществляться только внутри коммутатора без появления на стековой шине. Для коммутаторов 3750v2 пакеты между локальными портами по старинке будут проходить через всю стековую шину.
Давайте кратко коснёмся схемы работы стека на программном уровне. В рамках стека StackWise или StackWise Plus один из коммутаторов выбирается в качестве мастера (stack master). Он выполняет логические операции (control-plane) для всего стека. При его отказе передача unicast трафика продолжается. Это достигается благодаря синхронизации аппаратных таблиц. Между коммутаторами стека синхронизируются MAC-таблица, а также таблицы Cisco Express Forwarding (CEF), а именно FIB и Adjacency table. А вот остальные таблицы, в том числе таблица маршрутизации, таблица передачи multicast трафика, на новом мастере заполняются заново. При этом возможно использование функционала NSF — Nonstop Forwarding. Т.е. control-plane на новом мастере запускается с нуля.
На этом предлагаю прерваться. Продолжение появится в ближайшие дни.
- kpet-ks.ru
- Компьютерные сети. г.Котово
- Коммутаторы, шины, интерфейсы
- КЛАССИФИКАЦИЯ ИНТЕРФЕЙСОВ
- ВНУТРЕННИЕ ИНТЕРФЕЙСЫ
- ШИНА ISA
- ШИНА EISA (EXTENDED INDUSTRY STANDARD ARCHITECTURE)
- ШИНА МСА (MICROCHANNEL ARCHITECTURE)
- ЛОКАЛЬНЫЕ ШИНЫ
- ЛОКАЛЬНАЯ ШИНА VESA (VL-BUS)
- ШИНА PCI (PERIPHERAL COMPONENT INTERCONNECT BUS)
- PCI EXPRESS (PCX)
- ИНТЕРФЕЙС PCMCIA
- AGP (ACCELERATED GRAPHICS PORT)
- КОНТРОЛЛЕР HYPERTRANSPORT
- 🔍 Видео
Видео:Лекция "Интерфейсы (часть I). RS-232/422/485. SPI"Скачать

kpet-ks.ru
Компьютерные сети. г.Котово
Видео:Цифровые интерфейсы и протоколыСкачать

Коммутаторы, шины, интерфейсы
КЛАССИФИКАЦИЯ ИНТЕРФЕЙСОВ

Связь устройств автоматизированных систем друг с другом осуществляется с помощью средств сопряжения, которые называются интерфейсами. Интерфейс представляет собой совокупность линий и шин, сигналов, электронных схем и алгоритмов (протоколов), предназначенную для осуществления обмена информацией между устройствами.
В соответствии с функциональным назначением интерфейсы можно поделить на следующие основные классы:
- системные интерфейсы ЭВМ;
- периферийного оборудования (общие и специализированные);
- программно-управляемых модульных систем и приборов;
- интерфейсы сетей передачи данных и другое.
Предполагаю здесь рассмотреть внутренние интерфейсы (шины), внешние интерфейсы (порты) и интерфейсы процессоров. Интерфейсы мониторов (и видеопроекторов) рассмотрены далее.
Различные микросхемы и устройства, образующие персональный компьютер, должны быть соединены друг с другом таким образом, чтобы они имели возможность обмениваться данными и целенаправленно управляться. Эта проблема решена путем применения унифицированных шин. Используется набор проводников (на системной плате это печатные проводники), к которым подключены разъемы – гнезда (socket) или слоты (slot). В слоты расширения могут вставляться платы адаптеров (контроллеров) отдельных устройств и, что особенно важно, новых устройств. Таким образом, любой компонент, вставленный в слот, может взаимодействовать с каждым подключенным к шине компонентом персонального компьютера.
Шина представляет собой набор проводников (линий), соединяющий различные компоненты компьютера для подвода к ним питания и обмена данными. В минимальной комплектации шина имеет три типа линий:
Обычно системы включают два типа шин:
- системная шина, соединяющая процессор с ОЗУ и кэш памятью 2-го уровня;
- множество шин ввода-вывода, соединяющие процессор с различными периферийными устройствами. Последние соединяет с системной шиной мост, который встроен в набор микросхем (chipset), обеспечивающий функционирование процессора.
Системная шина при архитектуре DIB (Dual independent bus) физически разделена на две:
- первичную шину (FSB, Frontside bus), связывающую процессор с ОЗУ и ОЗУ с периферийными устройствами;
- вторичную шину (BSB, Backside bus) для связи с кэш памятью L2.
Использование двойной независимой шины повышает производительность за счет возможности для процессора параллельно обращаться к различным уровням памяти. Обычно термины «FSB» и «системная шина» используют как синонимы.
Следует отметить, что терминология, используемая в настоящее время для описания интерфейсов, не является вполне однозначной и ясной. Системная шина часто упоминается как «главная шина», «шина процессора» или «локальная шина». Для шин ввода-вывода используются термины «шина расширения», «внешняя шина», «хост-шина» и опять же – «локальная шина».
Устройства, подключенные к шине, делятся на две основные категории – bus masters и bus slaves. Bus masters – это активные устройства, способные управлять работой шины, то есть инициировать запись/чтение и так далее Bus slaves – соответственно устройства, которые могут только отвечать на запросы.
Если для вас это все сложно то лучше заказать специалиста, который проведет диагностику вашего компьютера.
ВНУТРЕННИЕ ИНТЕРФЕЙСЫ
Интерфейсы, характеристики которых приводятся в таблице, относятся к внутренним.
Таблица основных характеристик внутренних интерфейсов
| Стандарт | Типичное применение | Пиковая пропускная способность | Примечания |
|---|---|---|---|
| ISA | Звуковые карты, модемы | От 2 до 8.33 Мбайт/с | Практически не используется, начиная с 1999 года |
| EISA | Сети, адаптеры SCSI | 33 Мбайт/с | Практически не используется, замещается PCI, LPC |
| LPC | Последовательный и параллельный порты, клавиатура, мышь, контроллер НГМД | Как ISA/EISA | Предложена Intel в 1998 году как замена для шины ISA |
| PCI | Графические карты, адаптеры SCSI, звуковые карты новых поколений | 133 Мбайт/с (32-битовая шина с частотой 33 МГц) | Стандарт для периферийных устройств |
| PCI-X | Тоже | 1 Гбайт/с (64-битовая шина с частотой 133 МГц) | Расширение PCI, предложенное IBM, HP, Compaq. Увеличена скорость и количество устройств |
| PCI Express | До 16 Гбайт/с Разработка «интерфейса 3-го поколения» (Third generation Input/Output – 3GIO), может заменить AGP. | Последовательная шина | |
| AGP | Графические карты | 528 Мбайт/с 2x-mode (2 годаафические карты) | Стандарт для Intel-PC, начиная с Pentium 2 сосуществует с PCI |
| AGP PRO | ЗD-графика | 800 Мбайт/с (4x-mode) | Поддерживает видеокарты, требующие мощность до 100 Вт (AGP – до 25 Вт) |
| HT (Гипер Транспорт) | Универсальный интерфейс | До 32 Гбайт/с | Разработка AMD для процессоров К7-К8 |
ШИНА ISA
ISA BUS (Industry Standard Architecture) – стандартные шины IBM PC XT (8 бит) и AT (16 бит).
- 8-битовую шину данных;
- 20-битовую шину адреса, что позволяет адресоваться к 2 20 бит (1 Мбайт) памяти;
- три канала прямого доступа к памяти (DMA);
- тактовую частоту 8 МГц;
- пропускную способность 4 Мбайт/с;
- 62-контактный разъем.
В настоящее время XT практически не применяется. В компьютерах AT шину расширили до 16 бит данных и 24 бит адреса. В таком виде она существует и поныне как самая распространенная шина для периферийных адаптеров. Шина AT имеет:
- 6-битовую шину данных;
- 24-битовую шину адреса, что позволяет адресовать 16 Мбайт памяти;
- 8 каналов прямого доступа (DMA);
- тактовую частоту 8-16 МГц.
ШИНА EISA (EXTENDED INDUSTRY STANDARD ARCHITECTURE)
Шина EISA явилась «асимметричным ответом» производителей клонов PC на попытку IBM поставить рынок под свой контроль путем выпуска МСА. В сентябре 1988 года производители компьютеров – Compaq, Wyse, AST Research, Tandy, Hewlett-Packard, Zenith, Olivetti, NEC и Epson – представили совместный проект: 32-разрядное расширение шины ISA с полной обратной совместимостью. Основные характеристики новой шины:
- 32-разрядная передача данных;
- максимальная пропускная способность 33 Мбайт/с;
- 32-разрядная адресация памяти позволяла адресовать до 4 Гбайт;
- поддержка многих активных устройств (bus master);
- возможность задания уровня двухуровневого (edge-triggered) прерывания (что позволяло нескольким устройствам использовать одно прерывание, как и в случае многоуровневого (level-triggered) прерывания);
- автоматическая настройка плат расширения.
Читайте также: Нарезка грузовых шин в челябинске
ШИНА МСА (MICROCHANNEL ARCHITECTURE)
MCA – микроканальная архитектура – была введена в пику конкурентам фирмой IBM для своих компьютеров PS/2 начиная с модели 50. Шина МСА несовместима с ISA/EISA и другими адаптерами.
Эта шина не обладала обратной совместимостью с ISA, но содержала ряд передовых для своего времени решений:
- 8/16/32-разрядную передачу данных;
- пропускную способность 20 Мбайт/с при частоте шины 10 МГц;
- поддержку нескольких активных устройств.
Работу координирует устройство, называемое арбитром шины (САСР – Central Arbitration Control Point). При распределении функций управления шиной арбитр исходит из уровня приоритета, которым обладает то или иное устройство или операция.
Всего таких уровней четыре (в порядке убывания):
- регенерация системной памяти;
- прямой доступ к памяти (DMA);
- платы адаптеров;
- процессор.
Сразу же после выхода шины EISA началась «шинная война», причем это была не столько война между архитектурами (они обе ушли в прошлое), сколько война за контроль IBM над рынком персональных компьютеров. Эту войну корпорация проиграла, хотя архитектура МСА по заложенным техническим решениям и перспективам развития выглядела предпочтительнее. Вот сравнительная характеристика двух шин:
| Пропускная способность, Мбайт/с | MCA 20 | EISA 33 |
|---|---|---|
| Способ передачи данных | Асинхронный | Синхронный |
| Размер карты (длина х ширина), мм | 292.1 х 88.2 | 333.5 х 127.0 |
Поскольку поверхности карты EISA в 1.65 раза больше, а адаптер EISA мог потреблять в 2 раза больше мощности, чем адаптер МСА, выпускать периферию под EISA оказалось проще и дешевле.
Кроме того, в «шинной войне», как и везде, присутствует «рука Intel». В стремлении освободить рынок для новых процессоров 80386 и 80486 Intel выпускала EISA-чипсеты, не поддерживающие 286 процессор, в то время как шина МСА прекрасно работала и на компьютерах с 286. Таким образом, перспективная разработка IBM так и осталась перспективной, но и шина EISA не получила широкого распространения: к тому времени, когда потребности компьютеров среднего уровня переросли возможности шины ISA, разработчики перешли, минуя EISA, к локальным шинам.
Шина Low Pin Count («малоконтактный» интерфейс), или LPC, используется на IBM совместимых персональных компьютерах для подсоединения низкоскоростных устройств, таких, как «преемственные» (legacy) устройства ввода-вывода (последовательный и параллельный порты, клавиатура, мышь, контроллер НГМД). Физически LPC обычно подсоединяется к чипу «Южного моста». Шина LPC была предложена Intel в 1998 году как замена для шины ISA.
Спецификация LPC определяет 7 электросигналов для двунаправленной передачи данных, 4 из которых несут мультиплексированные адрес и данные, оставшиеся 3 – управляющие сигналы (кадр, сброс, синхросигнал).
Шина LPC предусматривает только 4 линии вместо 8 или 16 для ISA, но она имеет полосу пропускания ISA (33 МГц). Другим преимуществом LPC является то, что количество контактов для присоединяемых устройств равно 30 вместо 72 для эквивалента ISA.
ЛОКАЛЬНЫЕ ШИНЫ
Попытки улучшить системные шины за счет создания шин MCA и EISA имели ограниченный успех и кардинальным образом не решали проблемы. Все описанные ранее шины имеют общий недостаток – сравнительно низкую пропускную способность, поскольку они разрабатывались в расчете на медленные процессоры, В дальнейшем быстродействие процессора возрастало, а характеристики шин улучшались в основном экстенсивно, за счет добавления новых линий. Препятствием для повышения частоты шины являлось огромное количество выпущенных плат, которые не могли работать на больших скоростях обмена (МСА это касается в меньшей степени, но в силу вышеизложенных причин эта архитектура не играла заметной роли на рынке). В то же время в начале 90-х годов в мире персональных компьютеров произошли изменения, потребовавшие резкого увеличения скорости обмена с устройствами:
- создание процессоров Intel 80486, работающих на частотах до 66 МГц;
- увеличение емкости жестких дисков и создание более быстрых контроллеров;
- разработка и активное продвижение на рынок графических интерфейсов пользователя (типа Windows или операционной системы/2) привели к созданию новых графических адаптеров, поддерживающих более высокое разрешение и большее количество цветов (VGA и SVGA).
Очевидным выходом из создавшегося положения является следующий: осуществлять часть операций обмена данными, требующих высоких скоростей, не через шину ввода-вывода, а через шину процессора, примерно так же, как подключается внешний кэш. При этом шина работает с частотой, соответствующей тактовой частоте процессора. Передачей данных управляет не центральный процессор, а плата расширения (мост), который высвобождает микропроцессор для выполнения других работ. Локальная шина обслуживает наиболее быстрые устройства: память, дисплей, дисковые накопители при этом обслуживание сравнительно медленных устройств – мышь, модем, принтер и другое – производится системной шиной типа ISA (EISA).
Такая конструкция получила название локальной шины (Local Bus).
Отсутствие стандарта сдерживало распространение локальных шин, поэтому ассоциация VESA (Video Electronic Standard Association), представляющая более 100 компаний, предложила в августе 1992 года свою спецификацию локальной шины.
ЛОКАЛЬНАЯ ШИНА VESA (VL-BUS)
Исторически появилась первой и была создана специально для лучшего микропроцессора того времени 480DX/2. В зависимости от используемого центрального процессора тактовая частота шины может составлять от 20 до 66 МГц.
Стандарт шины VL 1.0 поддерживает 32-разрядный тракт данных, но его можно использовать и в 16-разрядных устройствах. Стандарт 2.0 рассчитан на 64-битовую шину в соответствии с новыми процессорами. Спецификация 1.0 ограничена частотой 40 МГц, а 2.0 – 50 МГц. В спецификации 2.0 шина поддерживает до 10 устройств, 1.0 – только три. Устойчивая скорость передачи составляет до 106 Мбайт/с (для 64-разрядной шины – до 260 Мбайт/с).
Шина VL-bus явилась шагом вперед по сравнению с ISA как по производительности, так и по дизайну. Однако и эта шина не была лишена недостатков, главными из которых являлись следующие:
- ориентация на 486-й процессор. VL-bus жестко привязана к шине процессора 80486, которая отличается от шин Pentium и Pentium Pro/Pentium 2;
- ограниченное быстродействие. Как уже было сказано, реальная частота VL-bus не больше 50 МГц. Причем при использовании процессоров с множителем частоты шина использует основную частоту (так, для 486DX2-66 частота шины составит 33 МГц);
- схемотехнические ограничения. К качеству сигналов, передаваемых по шине процессора, предъявляются очень жесткие требования, соблюсти которые можно только при определенных параметрах нагрузки каждой линии шины;
- ограничение количества плат, вытекающее из необходимости соблюдения ограничений на нагрузку каждой линии.
ШИНА PCI (PERIPHERAL COMPONENT INTERCONNECT BUS)
Разработка шины PCI закончилась в июне 1992 года как внутренний проект корпорации Intel. Основные возможности шины следующие:
- синхронный 32- или 64-разрядный обмен данными (64-разрядная шина в настоящее время используется только в Alpha-системах и серверах на базе процессоров Intel Xeon). При этом для уменьшения числа контактов (и стоимости) используется мультиплексирование, то есть адрес и данные передаются по одним и тем же линиям;
- частота работы шины 33 или 66 МГц (в версии 2.1) позволяет обеспечить широкий диапазон пропускных способностей (с использованием пакетного режима);
- полная поддержка многих активных устройств (например, несколько контроллеров жестких дисков могут одновременно работать на шине);
- спецификация шины позволяет комбинировать до восьми функций на одной карте (например, видео, звук и так далее).
- а – разъем 32-разрядной шины с напряжением питания 5 В;
- б – то же с напряжением питания 3.3 В;
- в – типичное PCI-устройство.
Известны также более поздние разновидности – РС1-Х и PCI-Express, кроме того, к данному типу относится и PCMCIA – стандарт на шину для ноутбуков. Она позволяет подключать расширители памяти, модемы, контроллеры дисков и стримеров, SCSI-адаптеры, сетевые адаптеры и другие.
PCI-X не только увеличивает скорость PCI-шины, но также и число высокоскоростных слотов. В обычной шине РС1-слоты работают на 33 МГц, а один слот может работать при 66 МГц. PCI-X удваивает производительность стандарта PCI, поддерживая один 64-битовый слот на частоте 133 МГц, а общую производительность увеличивает до 1 Гбайт/с. Новая спецификация также предлагает расширенный протокол для увеличения эффективности передачи данных и снизить требования к электропитанию.
PCI EXPRESS (PCX)
Стандарт PCX определяет гибкий, масштабируемый, высокоскоростной, последовательный, «горячего подключения» интерфейс, программно-совместимый с PCI. В отличие от предшественника, PCX поддерживает систему связи «точка-точка», подобную ГиперТранспорту AMD, а не многоточечную схему, используемую в параллельной шинной архитектуре. Это устраняет потребность в шинном арбитраже, обеспечивает низкое время ожидания и упрощает «горячее» подключение-отключение системных устройств.
Читайте также: Туалетная вода шине бомбита
Ожидается, что одним из последствий этого будет сокращение площади платы на 50%. Топология шины PCX содержит главный мост (Host Bridge) и несколько оконечных пунктов (устройств ввода-вывода). Многократные соединения «точка-точка» вводят новый элемент – переключатель (ключ, switch) в топологию системы ввода-вывода.
Интерфейс PCX включает пары проводов – каналы (lane), и единственная пара (PCX-lane) представляет собой интерфейс РСХ 1х (800 Мбайт/с). Каналы могут быть соединены параллельно, и максимум (32 канала – PCX 32х) обеспечивает полную пропускную способность 16 Гбайт/с, достаточную, чтобы поддерживать требования систем связи в обозримом будущем.
Одним из направлений развития PCX является замена AGP. Действительно, 8 Гбайт/с двунаправленной пропускной способности достаточно для поддержки телевидения высокого разрешения (HDT). При этом данные технологии характеризуются следующими особенностями:
- AGP – разделение полос пропускания для записи и чтения; общая полоса пропускания – 2 Гбайт/с; оптимизировано для однозадачного режима.
- PCI Express – выделенные полосы для ввода и вывода; общая полоса пропускания до 8 Гбайт/с; оптимизировано для многозадачного режима.
Предполагается также, что PCI Express в дальнейшем сможет заменить в чипсетах контроллер внешних устройств «Southbridge», но это не повлияет на функции контроллера оперативной памяти «Northbridge».
ИНТЕРФЕЙС PCMCIA
С появлением портативных компьютеров возникла проблема универсального и компактного интерфейса для подключения внешних устройств. В качестве такого интерфейса стандартом де-факто стал интерфейс PCMCIA, поддерживаемый Ассоциацией PCMCIA (Personal Computer Memory Card International Association), объединяющей компании, разрабатывающие периферийные устройства для портативных компьютеров. Аббревиатура PCMCIA вызывала много нареканий своей труднопроизносимостью. Существует даже шутливая интерпретация PCMCIA как «People Can`t Memorize Computer Industry Acronyms», что переводится как «Люди не в состоянии запомнить компьютерные аббревиатуры». В результате для PCMCIA сегодня принято использовать более благозвучный термин PC Card.
Устройства PC Card размером с обычную кредитную карточку являются альтернативой обычным платам расширения, подключаемым к шине ISA. В этом стандарте выпускаются модули памяти, модемы и факс-модемы, SCSI-адаптеры, сетевые карты, звуковые карты, винчестеры (IBM Microdrive), интерфейсы CD-ROM и так далее.
Первая версия стандарта PC Card для связи между картой и соответствующим устройством (адаптером или портом) компьютера определяет 68-контактный механический соединитель. На нем выделены 16 разрядов под данные и 26 разрядов под адрес, что позволяет непосредственно адресовать 64 Мбайта памяти. На стороне модуля PC Card расположен соединитель-розетка, а на стороне компьютера соединитель-вилка. Кроме того, стандарт определяет три различные длины контактов соединителя-вилки. Поскольку подключение и отключение PC Card может происходить при работающем компьютере (так называемое «горячее»), то для того, чтобы на модуль сначала подавалось напряжение питания, а лишь затем напряжение сигнальных линий, соответствующие контакты выполнены более длинными.
Вторая версия спецификации PC Card предусматривает три разновидности.
Таблица размеров карт второй версии PC Card
| Тип карты | Длина в миллиметрах |
|---|---|
| Type 1 | 85.6 (3.37«) 54(2.12») 3.3 в середине и 3.3 по краям |
| Туре 2 | 85.6 (3.37») 54(2.12») 5.0 в середине и 3.3 по краям |
| Type 3 | 85.6 (3.37») 54(2.12») |
AGP (ACCELERATED GRAPHICS PORT)
Несмотря на разрядность и скорость шины PCI, оставалась проблема, которая превышала ее возможности – выдача графической информации. Если адаптер CGA (4=2 2 цвета, экран 320 х 200 точек, частота 60 Гц) требует пропускную способность 2 х 320 х 200 х 60=7 680 000 бит/с=960 Кбайт/с, адаптер XGA (2 16 цветов, экран 1024 x 768 пикселей, частота 75 Гц) требует 16 x 1024 x 758 x 75=9 433 718 400 бит/с
118 Мбайт/с. В то же время пиковая пропускная способность РС1 составляла до 132 Мбайт/с.
Фирмой Intel было предложено решение в виде AGP – Accelerated graphics port (порт ускоренного графического вывода). Появление шины AGP в начале 1998 года было своеобразным прорывом в области графических работ. При частоте шины в 66 МГц она была способна передавать два блока данных за один такт. Пропускная способность шины составляет 500 Мбайт/с (V2.0) при двух режимах работы: DMA и Execute. Основным же преимуществом AGP является возможность хранения текстур в оперативной памяти. При этом скорости работы шины AGP хватает для их своевременной передачи в видеопамять (работа в режиме DMA). В режиме Execute оперативная и видеопамять воспринимаются как равноправные. Текстуры выбираются блоками 4 Кбайт из общей памяти с помощью таблицы GART (Graphic Adress Re-mapping Table) и передаются, минуя локальную память видеокарты. На сегодняшний день существует стандарт (поддерживаемый новыми чипсетами Intel и Via) AGP4x, позволяющий повысить пропускную способность до 1 Гбайт/с.
Схемы AGP взаимодействуют непосредственно с четырьмя источниками информации (Quadra port acceleration):
- процессором (кэш память 2-го уровня);
- оперативной памятью;
- графической картой AGP;
- шиной PCI.
AGP функционирует на скорости процессорной шины (FSB). При тактовой частоте 66 МГц, например, это в 2 раза выше, чем скорость PCI, и позволяет достигать пиковой пропускной способности в 264 Мбай/с. В графических картах, специально спроектированных для AGP, передача происходит как по переднему, так и по заднему фронту тактовых импульсов центрального процессора, что позволяет при частоте 133 МГц осуществлять передачу со скоростью до 528 Мбайт/с (это называется «2-х графика»). В дальнейшем была выпущена версия AGP 2.0, которая поддерживала «4-х графику» или четырехкратную передачу данных за один такт центрального процессора.
КОНТРОЛЛЕР HYPERTRANSPORT
Фирмой AMD была (процессор Hammer) предложена архитектура ГиперТранспорт (HyperTransport), обеспечивающая внутреннее соединение процессоров и элементов чипсета для организации многопроцессорных систем и повышения скорости передачи данных более чем в 20 раз.
В традиционной архитектуре с северным и южным мостами транзакции памяти должны проходить через микросхему «Северного моста», что вызывает дополнительные задержки и снижает потенциальную производительность. Чтобы избавиться от этого «узкого места» производительности, корпорация AMD интегрировала контроллер памяти в процессоры AMD64. Прямой доступ к памяти позволил существенно уменьшить задержки при обращении процессора к памяти. С увеличением тактовой частоты процессоров задержки станут еще меньше.
В основу шины HyperTransport – универсальной шины межчипового соединения – положено две концепции: универсальность и масштабируемость. Универсальность шины HyperTransport заключается в том, что она позволяет связывать между собой не только процессоры, но и другие компоненты материнской платы. Масштабируемость шины состоит в том, что она дает возможность наращивать пропускную способность в зависимости от конкретных нужд пользователя.
Устройства, связываемые по шине HyperTransport, соединяются по принципу «точка-точка» (peer-to-peer), что подразумевает возможность связывания в цепочку множества устройств без использования специализированных коммутаторов. Передача и прием данных могут происходить в асинхронном режиме, причем передача Данных организована в виде пакетов длиной до 64 байт. Масштабируемость шины HyperTransport обеспечивается посредством магистрали шириной 2.4, 8.16 и 32 бит в каждом направлении. Кроме того, предусматривается возможность работы на различных тактовых частотах (от 200 до 800 МГц). При этом передача данных происходит по обоим фронтам тактового импульса. Таким образом, пропускная способность шины HyperTransport меняется от 200 Мбайт/с при использовании частоты 200 МГц и двух двухбитовых каналов до 12.8 Гбайт/с при использовании тактовой частоты 800 МГц и двух 32-битовых каналов.
Демонстрирует, насколько разводка для ГиперТранспорта экономичнее, чем для традиционных шин – достаточно сравнить площади, занимаемые на системной плате шиной AGP 8х с пропускной способностью 2 Гбайт/с и ГиперТранспорт (до 6.4 Гб
Читать так же
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО ТЕМЕ «ВНУТРЕННИЕ ИНТЕРФЕЙСЫ»
- Интерфейс. Определение. Представление и обслуживание.
- Чем отличаются шины в настоящее время?
- Системная шина GTL. Назначение. Характеристики.
- Шина Н y ре r Т r а nsport . Назначение. Характеристики. Уровни интерфейса. Типы физических устройств. Параметры.
- Шина чипсета. Назначение. Характеристики. Требования. Виды.
- Шина ISA /Е ISA . Назначение. Характеристики.
- Шина РС I . Назначение. Характеристики.
- Шина А G Р. Назначение. Характеристики.
- Шина РС I Ехр r ее s . Назначение. Характеристики.
- Шина АТА( IDE ). Назначение. Характеристики.
- Шина Serial АТА. Назначение. Характеристики.
- Шина SCSI . Назначение. Характеристики.
- Шина Serial Attached SCSI. Назначение . Характеристики. Отличительные черты.
- Интерфейс АСР I . Назначение. Характеристики.
- Шина SM В us . Назначение. Характеристики.
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО ТЕМЕ «ВНЕШНИЕ ИНТЕРФЕЙСЫ»
- Шина СОМ. Назначение. Основные характеристики.
- Интерфейс IrDA. Назначение. Основные характеристики.
- Шина LРТ. Назначение. Основные характеристики.
- Шина USB. Назначение. Основные характеристики.
- Шина FireWire. Назначение. Основные характеристики.
- Порт Bluetooth. Назначение. Основные характеристики.
🔍 Видео
Вебинар: Типовые схемы настройки SwitchСкачать
15 Параллельные и последовательные интерфейсыСкачать

Лекция 308. Шина I2CСкачать

55. Знакомство с интерфейсом 1-wire (Урок 46. Теория)Скачать

Лекция 256. Интерфейс RS-485Скачать

Маршрутизатор. Коммутатор. Хаб. Что это и в чем разница?Скачать

интерфейс rs 485 и микроконтроллерыСкачать

Что такое VLAN, как работает коммутатор.Скачать

Raisecom - управляемые коммутаторы. Первоначальная настройкаСкачать

Лекция 307. Интерфейс SPIСкачать

Лекция 309. 1-wire интерфейсСкачать

Интерфейсы RS-485Скачать

Тема 11. Архитектура и исполнение коммутаторов.Скачать
Тема 10. Коммутация. Как работает коммутатор.Скачать

Вебинар E=DC2 №4: Технология SAN (Storage Area Network) и её применениеСкачать

Учим основы - что такое VLAN?Скачать

лекция 417 Чтение и запись данных на общую шинуСкачать

Цифровые интерфейсы и протоколыСкачать
