
Оперативная память (ОЗУ) является одним из важнейших компонентов компьютера, который напрямую влияет на эффективность его работы. В данной публикации мы рассмотрим, какая бывает оперативная память и на какие основные характеристики ОЗУ стоит обратить внимание при выборе. А также рассмотрим, какие бывают типы оперативной памяти, что такое частота, и на что влияют тайминги, но обо всем по порядку ниже.

- Основные параметры ОЗУ
- Режимы подключения ОЗУ
- Охлаждение
- Какой объем памяти обычно используется в ПК
- Вывод
- Контроллер памяти: структура и синхронизация
- Введение
- Для самых маленьких
- реклама
- Как устроена память
- реклама
- Механизм интерливинга и конвейерная шина памяти
- реклама
- Структура контроллера памяти
- реклама
- Синхронизация подсистемы памяти
- Источники
Основные параметры ОЗУ
Форм-фактор
На сегодняшний день существует два основных форм-фактора ОЗУ. Первый имеет маркировку DIMM – это более габаритная память в основном применяется в стационарных ПК. Второй стандарт называется SO-DIMM – это более компактная память, обычно она применяется в ноутбуках, в редких случаях в моделях ПК в компактном корпусе.

Стандарты оперативной памяти
На сегодняшний день в данном разделе следует упомянуть о двух последних стандартах. Это более старая память стандарта DDR 3 и, соответственно, более новый стандарт DDR 4. Конечно, если вы выбираете память на уже существующую платформу, то нужно исходить из поддерживаемых стандартов материнской платы. Но если вы находитесь на этапе выбора ПК, то конечно следует отдать предпочтение памяти DDR4, она обладает более высокими скоростными характеристиками, а также является более энергоэффективной, к примеру, по сравнению с DDR 3 она эффективнее на 20-30 процентов. Кстати, благодаря новым технологиям на одной планке DDR 4 могут разместиться чипы с общим объемом памяти до 128 ГБ (конечно в бытовом использовании таких планок не встретить). Что касается стандарта DDR 3, он в основном сейчас используется для увеличения производительного потенциала устаревающих ПК. DDR3 и DDR4 отличаются между собой размещением контактов.

Объем памяти и ОС
Ранее на компьютерах устанавливалась 32-разрядные операционные системы, которые неспособны распознать и использовать более 4 Гб оперативной памяти в независимости, сколько физически мы установим памяти в ПК. В современных 64-разрядных операционных системах есть возможность установить в разы больше памяти, к примеру, Windows 10 имеет поддержку до 512 Гб ОЗУ, что на практике в бытовых задачах еще не используется, и дает нам огромный своего рода потенциальный запас.
Объем памяти и материнская плата
Также не маловажным моментом при желании приобрести максимальный объем памяти для вашего ПК, является возможность совместимости с вашей материнской платой. Эти данные можно найти на самой материнской плате или в ее спецификации. Если спецификация утеряна ее электронный вариант можно найти в интернете. Еще одним способом узнать все характеристики вашего ПК и материнской платы в частности являются использование специальных утилитов, к примеру программы AIDA64.
Частота
Частота ОЗУ условно отображает, сколько происходит операций по пересылке данных за одну секунду. Соответственно чем выше частота, тем лучше. К примеру, максимальная частота на ОЗУ DDR 3 составляла 1866 MHz (в крайне редких отдельных случаях достигала 2133 MHz). А вот рабочая частота памяти DDR 4 составляет 2133–3200 MHz. Также при выборе следует помнить и учитывать какую частоту поддерживает ваш процессор и материнская плата. Если приобрести более скоростную память и установить на материнскую плату с поддержкой более низкой частоты, память не сможет реализовать свой потенциал, и автоматически будет работать с более низкой частотой. Поэтому при выборе обязательно обращайте внимание на этот момент, чтобы не переплатить деньги в пустую.
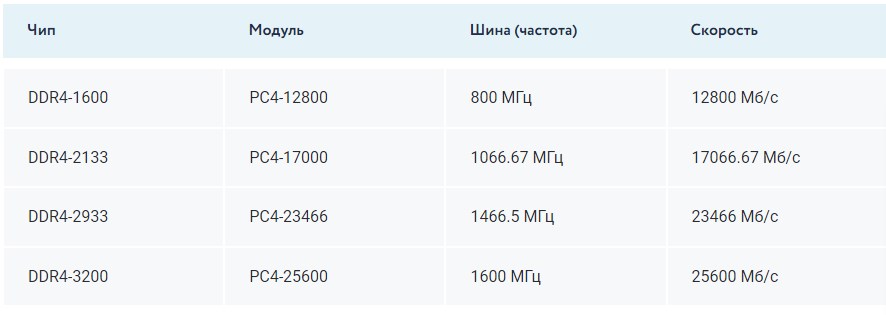
Пропускная способность
Пропускания способность ОЗУ, по сути, является комплексной характеристикой, которая рассчитывается как произведение объема данных, передаваемых за один такт, на частоту системной шины. Для наглядности ниже я добавил небольшую таблицу. К примеру, возьмем чип из таблицы DDR4-3200, он соответствует модулю PC4-25600. Таким образом, получается, что пропускная способность данной ОЗУ равна 25600. Чем выше пропускная способность, тем лучше.
Тайминги
В процессе работы ОЗУ, системе приходится выполнять своего рода подготовку к последующему обмену данными, как раз количество циклов для завершения этого процесса и характеризует показатель таймингов. Процесс подготовки данных делится на четыре этапа, задержка на каждом из которых и отображается в характеристиках таймингов. Углубляться в этих этапах я не буду, да и особого смысла в этом нет. Главное здесь нужно понимать, чем меньше тайминги, тем быстрее будет работать память. Стоит также добавить, что если вы приобретаете дополнительную планку памяти в ваш ПК, желательно подобрать аналогичные тайминги и частоту. Для примера, ниже на фото изображена планка ОЗУ с таймингами 9-9-9-24. Однако при выборе помните, что это далеко не самая главная характеристика и, на мой взгляд, не стоит сильно заострять на ней внимание.

Режимы подключения ОЗУ
Подключить ОЗУ к материнской плате можно одноканальным и многоканальным способами. Соответственно, чем больше каналов подключения, тем выше скорость работы ОЗУ, память как бы реализует весь свой потенциал. На данный момент в основном все используют двухканальный тип подключения. Для реализации этого режима нужно заведомо приобрести две одинаковые по характеристикам планки памяти, желательно от одного производителя, и подключить их в разные по цвету слоты. Если посмотреть на фото ниже, то первый слот будет осуществлять двухканальный режим с третьим, а второй слот соответственно с четвертым.

Охлаждение
Здесь мнения немного разделяются, некоторые считают, что чипы памяти рассчитаны на высокие температуры и если планки памяти изначально не комплектуются системами охлаждения, то они не требуются. Я считаю, что лишним охлаждение никогда не будет, и желательно сразу приобрести память со специальными алюминиевыми радиаторами для отвода лишнего тепла. При желании такие радиаторы можно приобрести отдельно. Также следует добавить, что радиаторы охлаждения могут быть оснащены декоративным освещением.


Какой объем памяти обычно используется в ПК
Сейчас еще можно встретить компьютеры с объемом оперативной памяти от 2 ГБ, но современные модели уже оснащены планками с общим объемом на 16 или 32 Гб.
- К примеру, если вам нужен современный игровой ПК, следует остановиться на объеме памяти от 16 ГБ, по возможности желательно взять память с запасом.
- Для выполнения профессиональных задач в современных графических редакторах или других требовательных программах следует выбрать ПК с объемом ОЗУ от 8 до 16 ГБ.
- Если вам нужен компьютер для решения повседневных задач, просмотра видео и серфинга по интернету, следует остановиться на объеме ОЗУ от 4 до 8 Гб.
Вывод
Подводя итог, скажу, что главное при выборе ОЗУ определится с задачами, которые вы будете выполнять на вашем компьютере. Исходя из этого, подбираем объем памяти, обращая внимание на частоту, пропускную способность и тайминги. Также нужно не забывать о совместимости вашей материнской палаты и ОЗУ. Ну, а на этом все, спасибо, что дочитали публикацию до конца. Больше интересных публикаций вы сможете найти в моем блоге на сайте.
Контроллер памяти: структура и синхронизация
Введение
Много ли вы слышали о контроллере памяти? Возможно, вы когда-то пытались найти информацию о контроллере памяти, но толком ничего не находили. Даже в книгах, к сожалению, есть только небольшие упоминания. Получается, что все знают про то, что контроллер памяти существуют, но никто не имеет представление, что это такое (именно на таких читателей рассчитана данная статья). Мне повезло наткнуться на статьи инженеров, которые решают проблемы проектирования и синхронизации контроллеров памяти в своих проектах. Эту информацию мы используем, чтобы понять, как устроен и как работает КП на высоком уровне.
Читайте также: Вид компьютерной сети шина кольцо звезда ромашка
Для самых маленьких
реклама
Процессору необходимо обращаться в память, как для получения инструкций, так и для данных, требуемых при исполнении инструкций. В качестве памяти может служить и основная оперативная память. Здесь появляется контроллер памяти, обрабатывающий запросы процессора. В общем-то о его предназначении вы узнаете, если прочитаете статью полностью.
Как устроена память
Во-первых, разберёмся с тем, как устроена память в принципе. Вы наверняка знаете, что у плашки оперативной памяти есть чипы памяти. Характеристика «плотность чипов» как раз обозначает объём в чипе памяти. Всё просто. Если есть чипы, емкость которых по 8 гигабит каждая (по одному гигабайту каждая), то 8 таких в сумме дадут 8 гигабайт (64 гигабит), поэтому мы и скажем, что это плашка на 8гб. Сам чип состоит из нескольких банок, а в свою очередь банки состоят из совокупности ячеек. Объём всех ячеек в чипе памяти одинаковый, причем ячейка по объёму не обязательно равна одному биту.
В современной памяти применяется матричная организация, то есть ячейки представлены в виде матрицы со столбцами и строками. Для обращения к памяти нужно задать адрес, чтобы память поняла, в какой её области мы хотим получить данные (или записать). Также требуется управляющий сигнал, чтобы выбрать, считывать мы будем или записывать и, естественно должны быть управляющие сигналы для выбора чипа, банка, страницы, отдельного слова. Управляющими сигналами мы выбираем все выше перечисленное, ведь когда банков несколько, то нужно выбрать конкретный банк и т.д, а по адресным линиям передаем адрес слова (или столбца, а затем строки последовательно) внутри банка. В случае матричной организации ячеек требуются сигналы RAS и CAS, где первый для выбора строки, а второй для выбора столбца. Когда задан сигнал RAS, должна происходить передача адреса строки. Аналогично, когда задан сигнал CAS, должна происходить передача адреса столбца. В такой реализации адресных линий будет меньше, так как адрес короче, зато нужно два цикла адресации, то есть на первом цикле выбрать строку матрицы, а на втором — столбец матрицы. Некоторые ошибочно полагают, что матрица обязательно должна быть квадратной, но это не так. Ниже приложен рисунок чипов памяти одного объема, но с разной реализацией
реклама
Группа A линий нужны для задания адреса (здесь мы посылаем 12-битный адрес)
D — для данных (здесь выводится 16 или 4 бит данных)
RAS — для строки
CAS — для столбца
банки — для банков (тут 4 банка. По двум линиям мы передаем два бита информации. Если подаем 00, то выбирается первый банк, 01 — второй, 10 — третий, 11 — четвертый)
CS (Chip Select) — для чипа (так как чипов на плашке памяти несколько. Обращение происходит к тому чипу, у какого задан сигнал CS)
WE (Write Enable) — для выбора записи или чтения (0 — чтение, 1 — запись)
OE (Output Enbale) — для разрешения вывода данных.
Важно сказать, что в реальности данные и адреса не направлены в разные стороны. Это единая шина, у которой линии разделены соответственно на информационные (D) и адресные (A) линии. А могут быть не разделены, если применяется мультипелксная шина. В такой реализации и адреса, и данные передаются по одним и тем же линиям последовательно. Это может решить проблему расфазировки шины (когда данные приходят быстрее адреса), но мультиплекс будет медленнее. Помимо всего прочего в статье И.А Петрова упоминается DDR4 3DS, использующая стеки чипов (друг на друга кладутся), которые взаимодействуют через связь сквозь кремний (through silicon via, TSV). Один такой чип в стеке называется логическим ранком. Логической страницей называется матрица внутри банка.
Механизм интерливинга и конвейерная шина памяти
Теперь разбираемся с механизмом интерливинга. Из статьи И.А Петрова: «В каждом логическом банке (размером от 256 Мбайт до 2 Гбайт) можно одновременно задействовать лишь одну страницу памяти (8 Кбайт). Переход к другой странице в рамках одного логического банка возможен через 45–50 нс». Далее написано, что механизм интерливинга, то есть перемешивание страниц памяти, находящихся в других банках памяти, избавляет от этой проблемы. Сначала непонятно каким образом, но это действительно так. Оказывается, банки для того и были введены, чтобы осуществлять несколько параллельных запросов к ним. Это так называемая конвейерная архитектура шины памяти. Если вы знакомы с конвейерной архитектурой ядер процессора, тогда вы примерно понимаете насколько круто, что у памяти такая тоже есть.
реклама
Здесь CK — это линия, по которой идут импульсы от тактового генератора с определенной частотой. Можно сказать, что шина работает на частоте CK или синхронизируется по CK. Как мы видим, циклом шины является период от фронта (переход от логического 0 к 1, поднятие по импульсу) синхросигнала до фронта следующего синхросигнала. Группа управляющих линий обозначена CMD, адресных — ADDR, а информационных — DATA.
Запрос к памяти состоит из трёх этапов:
1) Открытие строки для подготовки к обращениям (ACT).
2) Обращение к отдельным словам строки или к нескольким словам при использовании пакетного режима (длина пакета фиксирована).
3) Закрытие строки (PRECHARGE) и подготовка к следующей активизации.
В нашем примере важно, чтобы фаза активизации (ACT) предшествовала фазе READ (или WRITE) на 2 цикла (обязательно смотрите на рисунок). Также известно, что данные готовы на следующем цикле после фазы READ (WRITE), а PRECHARGE происходит минимум на два цикла позже фазы READ (WRITE). Данные обязательные условия называются протоколом. Все операции занимают определенное число циклов шины, поэтому известно, когда получать данные, когда открывать и закрывать строку. Конвейерный режим нужен, чтобы исключить простои. Ещё раз смотрите на рисунок: без конвейерного режима на цикле 1 образовался бы пустой цикл. Вместо простоя происходит активизация строки из другого банка. Преимущества очевидны.
Структура контроллера памяти
реклама
Это КП планировшегося Эльбруса 16CB. В контроллерах памяти есть буферы записи и чтения (в нашем примере этот буфер расположен за пределами КП). Когда КП получает данные от основной ОЗУ, данные сначала помещаются в буфер чтения. Аналогично с записью: данные от ядер поступают в буфер записи. Буферы выступают в роли промежуточной памяти для хранения, так как удобно получать данные большего объёма. Ведь ядру, которому понадобились данные по адресу A, с большой вероятностью понадобятся данные по адресу A+1. Это так называемый принцип локальности, на нем также основывается принцип кэширования. Буфер записи в свою очередь реализует отложенную запись.
В реестре запросов, как ни странно, хранятся запросы обращения к основной памяти. Каждая ячейка реестра включает в себя адрес, тип операции, признак готовности данных для записи, возраст запроса и стадию обработки запроса.
Планировщик занимается тем, что выбирает порядок запросов так, чтобы сократить среднее время на обработку одной заявки. Как это достигается? С помощью последовательно соединенных фильтров планировщика. На выходе планировщика расположен блок формирования операций для шины памяти, в котором запросы полностью перекрываются (отсутствуют пустые циклы на шине, что уже было описано выше).
Читайте также: Шины nokian подделка или нет
В Эльбрус 16CB фильтры соединены в таком порядке:
фильтр ресурсов, задерживающий запросы, выполнение которых невозможно вследствие недостаточности объемов буферов чтения или записи
фильтр адресной зависимости, обеспечивающий корректную последовательность обращений в случае обращений по одному адресу (запросу по одному адресу должны выполняться последовательно. Представим ситуацию, что в реестр поступает запрос на запись данных в оперативную память на адрес A, а следующий запрос — чтение данных по адресу A. Без этого фильтра, так как чтение имеет более высокий приоритет над записью, считались бы устаревшие данные)
фильтр приоритета выполнения запроса в открытую страницу логического банка, исключающий дополнительные операции открытия страниц (ACT). Запрос отсеивается, если он попадает в закрытую страницу, хотя в то же время есть запросы, адресованные в открытую страницу. Данный фильтр минимизирует команды активизации, что и уменьшит среднее время обработки заявки в реестре.
фильтр на приоритет операций чтения. Чтение гораздо важнее записи для производительности, поэтому у планировщика в приоритете запросы чтения
фильтр протокольных блокировок, задерживающий запросы, нарушающий протокол (об этом было раньше и ещё будет позже)
фильтр возраста. Выбирается самый старший запрос, то есть, который вошёл раньше всех в реестр.
О фильтрах почти полностью скопировано со статьи И.А Петрова, но кое-где добавлены собственные пояснения. Ниже приложен схематичный рисунок планировщика
Теперь про протокольные блокировки. Когда мы говорили о конвейерной шине памяти, я написал, что есть некий протокол. Его необходимо соблюдать для каждого банка памяти с помощью счетчиков-таймеров внутри контроллера протокольных блокировок. Из книги Танебаума: «Как Core i7 узнает, когда следует ожидать возвращения данных команды READ и когда можно выдавать новый запрос к памяти? Для этого он осуществляет полное моделирование внутренней деятельности каждой подключенной микросхемы DDR3. Соответственно он ожидает возвращения данных в правильно выбранном цикле и знает, что операцию предзаряда не следует начинать раньше чем через два цикла после последней операции чтения. Core i7 может прогнозировать все эти события, потому что интерфейс памяти DDR3 работает синхронно, так что все операции занимают четко определенное количество тактов шины DDR3.»
Моделированием внутренней деятельности как раз занимается контроллер блокировок. Фильтр протокольных блокировок в планировщике использует это и отсеивает невозможные запросы. Основой динамической памяти (любая SDRAM DDR относится к динамической памяти) является конденсатор. Конденсатор может хранить заряд в течении короткого времени, иными словами может служить битом памяти. Ведь у бита, как и у конденсатора, есть два состояния. У конденсатора либо есть заряд (бит 1, логический 1), либо его нет (бит 0, логический 0). При считывании конденсатор разряжается, и если заряд был, то значение однобитной ячейки равно единице, и это значение мы можем использовать. Также после считывания нужно заряжать конденсатор заново, если заряд был (другими словами: значение однобитной ячейки должно быть равно одному, если её значение было равно одному до разрядки). Контроллер регенерации памяти как раз занимается тем, что выдает команды регенерации памяти.
Обычно для реализации многоканального режима работы устанавливают несколько рассмотренных нами одноканальных контроллеров памяти. Как, например, двухканальный контроллер памяти Эльбруса S2 включает по сути два отдельных контроллера памяти, находящиеся в одном блоке.
Синхронизация подсистемы памяти
В подсистеме памяти чаще всего различают три частотных домена: системный домен, домен контроллера памяти и домен самой памяти. Пример представлен ниже.
Решение проблемы синхронизации включает в себя следующие вопросы: какие тактовые частоты будут у доменов и каким образом они будут взаимодействовать в совокупности. От этого будет зависеть задержка обращения в память и максимально допустимая частота памяти, ведь частота контроллера памяти может её ограничить. Итак, синхронизация подсистемы памяти влияет на её эффективность.
Для начала рассмотрим проблему метастабильности на примере триггеров. Что такое триггеры? Это защелки, которые синхронизируются на фронте или спаде тактового импульса. Много непонятных слов? О том, как работают защелки знать не обязательно. Достаточно понимать, что защелка может хранить один бит информации. Но синхронная защелка может записать бит информации только тогда, когда на одном из входов защелки есть тактовый импульс. Таким образом, тактовый импульс является своего рода сигналом, что данные с входа данных можно записать. А триггер отличается тем, что ему нужен не весь тактовый импульс, а только его фронт или спад.
В нашем случае триггеры будут синхронизироваться по фронтам, так что далее рассматривать будем только фронт, но помним, что для спада всё то же самое.
Для правильной работы триггера необходимо, чтобы входные данные триггера некоторое время оставались неизменны до фронта импульса. Этот временной интервал называется Time Setup (Ts). Аналогично после фронта импульса данные также некоторое время должны оставаться неизменными, и это временное требование называется Time Hold (Th).
Если требования для входных данных выполняются, то на выходе триггера данные также появляются. А иначе верное выходное значение триггера устанавливается через большее время. Такое состояние называется метастабильностью. В метастабильном состоянии сигнал пребывает в состоянии, которое нельзя назвать ни логическим нулём, ни логической единицей. Дальнейшее распространение метастабильного сигнала может привести к сбою всей системы.
Данная проблема характерна для передачи данных между доменами с разными частотами. Вы узнаете почему позже, а пока просто покажу частоты доменов подсистемы памяти в разных проектах.
Эльбрус-С+:
системный домен с частотой 500 МГц (системная частота);
домен оперативной памяти, частота которого относится к системной как 4/5, 2/3, 3/5 или 1/2;
домен ядра контроллера оперативной памяти, отношение его частоты к частоте памяти равно 1/2.
Один из КП А.С Кожина:
Системный домен (System domain) – 800/1000 МГц
Домен оперативной памяти (DDR domain) – 800, 666, 533, 400 МГц
Домен ядра контроллера (MC domain) – частота в 2 раза ниже частоты памяти
Домен оперативной памяти ровно в два раза меньше эффективной частоты оперативной памяти.
В двух случаях мы наблюдаем подсистему памяти, частотные домены которой имеют разные частоты (логично).
Возвращаемся к проблеме метастабильности. На рисунке (а) мы видим, что фронт CLKB захватывает нестабильный сигнал DA. Временной интервал между фронтами оказался недостаточным. В итоге мы имеем метастабильный сигнал DB.
Одними из решений данной проблемы является добавление ещё одного триггера. Совокупность триггеров на приемной стороне образует синхронизатор (рисунок б). Дополнительный триггер помог избавиться от дальнейшего распространения метастабильности сигналов, ведь DB2 принимает правильное значение. Однако не всегда такой синхронизатор решает проблему метастабильности. Например, здесь.
В первом случае CLKB не успевает захватить сигнал данных DA, а во втором случае CLKB захватывает DA три раза, то есть по сути одиночную посылку воспринимает, как множество посылок. В первом случае наблюдается передача из высокочастного домена в низкочастотный домен, а во втором — из низкочастотного в высокочастотный. Рассмотрим другой метод.
Читайте также: Шины в литве ком
Стандартной, самой распространенной схемой пересинхронизации является асинхронный FIFO-буфер. Асинхронный FIFO-буфер отличается от синхронного тем, что асинхронный работает с двумя тактовыми доменами: wrclk и rdclk. Здесь представлен FIFO-буфер от Altera. Модуль Write Control Logic осуществляет передачу в блок памяти (на рисунке Altera Memory Block), а Read Control Logic обеспечивают прием данных. Write Pointer и Read Pointer содержат указатели на ячейки буфера, задействованные в данный момент времени.
W_ADR соответствует значению Write Pointer, R_ADR соответствует значению Write Read.
Так как буфер асинхронный, то и write control logic, и read control logic функционируют на разных частотных доменах (имеют разные частоты).
Блок Flag Logic служит для формирования информационных сигналов о заполнении. Ниже представлена та же схема на более низком уровне.
Сначала указатель записи формируется в модуле в GRAYCOUNTER в коде Грея. Код Грея характерен тем, что в последовательности предыдущее значение от данного отличается только одним битом.
То есть в двоичной системе счисления будет так:
000
001 (отличается от предыдущего(000) одним битом)
010 (отличается от предыдущего(001) уже двумя битами в двух позициях)
011
100 (а здесь данное слово отличается всеми тремя битами от предыдущего)
101
110
111
Тогда как в коде Грея это будет выглядеть вот так:
000
001
011
010
110
111
101
100
Если мы возьмем любое значение, то опять же увидим, что оно отличается от предыдущего и от следующего только одним битом в какой-либо позиции. А зачем он нужен здесь вы узнаете совсем скоро. Далее из GRAYCOUNTER данные указателя отправляются в приемник через шину wrptr_g, а приемник работает на другой частоте. Здесь под шиной мы понимаем только совокупность проводников, по которым идет по биту информации. Но для исключения метастабильности на этом этапе к каждой линии шины подведен дополнительный триггер на передающей стороне, на рисунке он также изображен, и три триггера на принимающей стороне (на рисунке синхронизатор). Тогда возможно такое (при изменении указателя записи, то есть данных в GRAYCOUNTER), что сигналы на линиях шины будут задержаны относительно друг-друга, а это приведет к тому, что в одних линиях приемник захватит новые значения, а в других — старые. А в коде Грея новое значение отличается всего на один бит. У нас будет всего два варианта: либо старое (пусть будет 011), либо новое значение (пусть будет 010). А это к сбою работы FIFO-буфера не приведет. Далее gray2bin модуль сможет преобразовать код Грея в двоичное число. Также в любом FIFO-буфере с помощью сравнений указателей записи и чтения, узнается пуст ли или полон буфер. Верхняя граница известна, а при равенстве указателей мы понимаем, что буфер пуст. Ведь нельзя считать пустотой буфер или записать данные в переполненный, так что устанавливаются флаги из Flag Logic.
Асинхронные FIFO-буферы используются очень часто из-за того, что они могут передать данные доменов с очень разным соотношением частот. Да и вообще это очень удобно, ведь можно их заказывать готовые. Но, к сожалению, задержки будут гораздо больше: прохождение сигналов через триггеры, преобразование в код Грея и обратно — это довольно долго.
Ещё один интересный метод пересинхронизации я вычитал из статьи А.С Кожина, какую я укажу в источниках. Этот метод использовался в Эльбрус-C+, он предусматривает метки (сигналы) для высокочастотного домена. Причем для входа высокочастотного домена предусматривается метка clabel_i, служащая для того, чтобы высокочастотный домен не воспринимал одну посылку, как несколько (об этом было сказано, когда мы рассматривали синхронизаторы). Для выхода высокочастотного домена используется метка clabel_o, гарантирующая, что низкочастотный приемник примет данные (об этом тоже было сказано).
Здесь метка clabel_o разрешает изменение данных на выходе триггеров со стороны высокочастотного домена (обращайте внимание на data_out). На следующем фронте импульса приемника (приемник работает на частоте 2/5 Fsys), данные захватываются (это второй импульс 2/5 Fsys. Соотнесите его с data_out). Таким образом выполняется передача данных из высокочастотного домена в низкочастотный.
Здесь важно правильно формировать метки, чтобы соблюдались следующие требования: новые данные на data_out не должны захватываться предыдущим фронтом импульса (если бы первый импульс 2/5 Fsys захватил данные вместо второго), новые данные должны успеть переключиться до следующего фронта импульса (такое произошло, если бы второй импульс cabel_o появился позже).
Всё аналогично при передаче из низкочастотного домена в высокочастотный. Только в этому случае метка cabel_i обеспечивает выбор только одного фронта высокой частоты. Метки формируются в специальном блоке формирования меток.
Он состоит из регистра (такая память, состоящая из триггеров). Значение в регистре определяет, в какие такты периода биений (T align) разрешено выдавать метку. Период биений здесь, как вы можете посмотреть на предыдущем рисунке с меткой cabel_o — это период, при котором совпадают фронты импульсов. Ширина регистра определяется количеством тактовых импульсов за период биений (в Fsys было 5 таких). Основная метка выдается на частоте большего домена. Сигнал mode задает режим работы блоку формирования в зависимости от частот передающего и принимающего доменов. Указатель (Pointer) указывает на значение регистра, отвечающее за состояние метки (будет ли выдана или нет). Сигнал beat — это комбинационный сигнал биений, который определяет начало периода биений. Он помогает восстановить правильное значение указателя, если в нем изменился разряд.
Также синхронизация невозможна без самого блока пересинхронизации. Здесь всё стандартно, но всё-таки требуется раскрыть передачу из одного домена в другой, когда частоты доменов близки. Близкими частоты будут, если на низкочастотный импульс приходится один фронт высокочастотного домена или f1/f2 f2). Прием/передача могут быть невозможны из-за несоблюдения временнЫх интервалов. В этом случае используются триггеры, задерживающие на половину такта данные, и дополнительная метка, определяющая, когда задержанные данные можно использовать.
Подобный метод пересихронизации не так удобен и универсален, как асинхронный FIFO-буфер, но зато имеет меньшие задержки.
На этом всё. Спасибо за внимание, критикуйте, обсуждайте и задавайте вопросы.
Источники
Архитектура компьютера, 6-ое издание, Э. Танебаум и Т. Остин (Отсюда я взял про триггеры и прочее на цифровом логическом уровне, устройство памяти и шины)
Контроллер памяти DDR2 SDRAM и его система синхронизации в составе системы на кристалле «Эльбрус-S2», А. С. Кожин (по факту источник-пустышка, отсюда впервые услышал про метки, но взял только картинку с кп)
Метастабильность триггера и межтактовая синхронизация, «nerudo» (статья с хабра. Взял отсюда картинку, где Ts и Th интервалы)
Как работает FIFO , «dsmv2014» (Тоже хабр. Взял картинку с указателями, чтоб было понятнее и про назначение флагов узнал.)
Одно- и двухпортовая память. FIFO-буфер. Проблемы метастабильности, юутб-канал «Электроника и наноэлектроника» (типо лекция, мне показалась она достаточно сомнительной, но разобраться действительно помогла)
Что такое кэш процессора, и как он работает, Сергей Пахомов (здесь было про промежуточную память)
Флэш-память на любой вкус, Сергей Пахомов (про регенерацию памяти на уровне конденсаторов)
- Свежие записи
- Нужно ли менять пружины при замене амортизаторов
- Скрипят амортизаторы на машине что делать
- Из чего состоит стойка амортизатора передняя
- Чем стянуть пружину амортизатора без стяжек
- Для чего нужны амортизаторы в автомобиле