
Всё течёт, всё меняется. В сфере компьютерных технологий эта фраза никогда не потеряет актуальности, равно как и девиз «Быстрее! Выше! Сильнее!». И действительно, последние несколько лет можно назвать «временами перемен» компьютерной индустрии. В полной мере это коснулось и такой специфичной области, как шины передачи данных.
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной» 1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне 2 ).
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом , он входит в состав набора системной логики ( чипсета ).
Используемая Intel в настоящее время эволюция FSB – QPB , или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц) 3 .
В архитектуре же AMD64 (и её микроархитектуре K8), используемой компанией AMD в своих процессорах линеек Athlon 64/Sempron/Opteron, применён революционно новый подход к организации интерфейса центрального процессора – здесь имеет место наличие в самом процессоре нескольких отдельных шин. Одна (или две – в случае двухканального контроллера памяти) шина служит для непосредственной связи процессора с памятью, а вместо процессорной шины FSB и для сообщения с другими процессорами используются высокоскоростные шины HyperTransport. Преимуществом данной схемы является уменьшение задержек (латентности) при обращении процессора к оперативной памяти, ведь из пути следования данных по маршруту «процессор – ОЗУ» (и обратно) исключаются такие весьма загруженные элементы, как интерфейсная шина и контроллер северного моста.
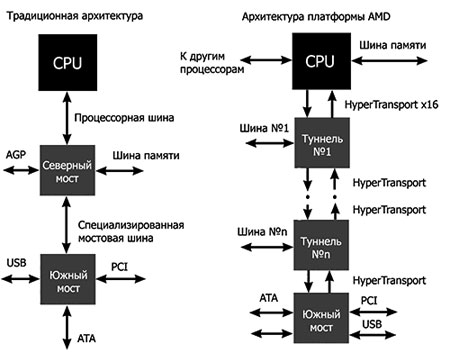
Различия реализации классической архитектуры и АМD-K8
Ещё одним довольно заметным отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора 4
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования 5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).
HyperTransport

Эмблема HyperTransport Technology Consortium
HyperTransport – это прежде всего технология, управлением спецификациями и продвижением которой занимается HyperTransport Technology Consortium, куда входят такие компании, как Advanced Micro Devices (AMD), Alliance Semiconductor, Apple Computer, Broadcom Corporation, Cisco Systems, NVIDIA, PMC-Sierra, Sun Microsystems, Transmeta и ещё более 140 малых и больших компаний.
Основные особенности и возможности, предоставляемые технологией HyperTransport
Технология HyperTransport (ранее известная как Lightning Data Transport) – это последовательная (пакетная) связь, построенная по схеме peer-to-peer (точка-точка), обеспечивающая высокую скорость при низкой латентности (low-latency responses). HyperTransport имеет оригинальную топологию на основе линков, тоннелей, цепей (цепь – последовательное объединение нескольких туннелей) и мостов (мост выполняет маршрутизацию пакетов между отдельными цепями), что позволяет этой архитектуре легко масштабироваться. Иными словами, HyperTransport призвана упростить внутрисистемные сообщения (передачи) посредством замены существующего физического уровня передачи существующих шин и мостов, а также снизить количество узких мест и задержек. При всех этих достоинствах HyperTransport характеризуется также малым числом выводов (low pin counts) и низкой стоимостью внедрения. HyperTransport поддерживает автоматическое определение ширины шины 6 , допуская ширину от 2 до 32 бит в каждом направлении, использует Double Data Rate, или DDR (данные посылаются как по переднему, так и по заднему фронтам сигнала синхронизации), кроме того, она позволяет передавать асимметричные потоки данных к периферийным устройствам и от них.
Читайте также: Сечение нулевой шины относительно фазной
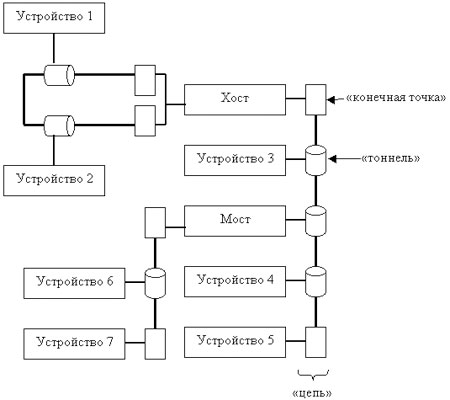
Топология шины HyperTransport
На данный момент консорциумом HyperTransport разработана уже третья версия спецификации, согласно которой шина HyperTransport может работать на частотах до 2,6 ГГц (сравните с шиной PCI и её 33 или 66 МГц). Это позволяет передавать до 5200 миллионов пакетов в секунду при частоте сигнала синхронизации 2,6 ГГц; частота сигнала синхронизации настраивается автоматически.
Полноразмерная (32-битная) полноскоростная (2,6 ГГц) шина способна обеспечить пропускную способность до 20800 МБ/с (2*(32/8)*2600) в каждую сторону, являясь на сегодняшний день самой быстрой шиной среди себе подобных.
Самые известные решения c использованием HyperTransport:
Использование шины НyperТransport на примере двухпроцессорной системы на базе AMD Opteron
Системная шина qpb что это
Front Side Bus (FSB) — это магистральный канал, обеспечивающий соединение процессора и внутренних устройств: памяти, видеокарты, устройств хранения информации и т. п.
Наиболее часто можно встретить систему организации внешнего интерфейса процессора, которая предполагает, что параллельная мультиплексированная процессорная шина, носящая название FSB, соединяет процессор (порой два процессора, четыре или даже больше) и системный контроллер, который обеспечивает доступ к оперативной памяти и внешним устройствам. Этот системный контроллер обычно называется «северным мостом» (от англ. Northbridge). Он, наряду с «южным мостом» (от англ. Southbridge), входит в состав набора системной логики, который, однако, чаще фигурирует под названием «чипсет» (от англ. Chipset).
Северный мост начал именоваться именно так из-за своего расположения на материнской плате. Он представляет собой микрочип, визуально расположенный «под» процессором, однако в верхней части материнской платы, как бы в «северной» ее части.
Системный контроллер служит для передачи команд центрального процессора к оперативной памяти, и видеоконтроллеру (в случае встроенного видеоконтроллера, северный мост, производимый компанией Intel, именуется GMCH (от англ. Chipset Graphics and Memory Controller Hub), а также конвертацию этих команд в форму, необходимую для обращения к оперативной памяти. Порой, для увеличения потенциальной производительности системы, к северному мосту подключаются наиболее производительные периферийные устройства, например, видеокарты с шиной PCI Express, а менее производительные устройства (BIOS, устройства PCI, интерфейсы устройств хранения информации, ввода и т. п.) могут подключаться к так называемому южному мосту. Северный мост соединен с материнской платой посредством согласующего интерфейса, также контроллер соединяется шиной и с южным мостом.
Северным мостом определяются параметры (пропускная способность, частота, а также тип): системной шины, оперативной памяти (тип используемой памяти, а также ее максимальный объем), подключенного видеоконтроллера (режим работы, возможность использования SLI (от англ. Scalable Link Interface, что означает «масштабируемый интерфейс» и фактически означает возможность работы 2 (3 — 3-Way SLI, или даже 4 — Quad SLI) видеоадаптеров одновременно, что чрезвычайно повышает производительность видео).
В настоящее время в процессорах серии Core i-x с разъемом LGA 1156 северный мост встроен в процессор и связывается с ядрами по внутренней шине QPI со скоростью соединения 2.5^109 операций в секунду. Из факта поглощения процессором северного моста вытекает неактуальность использования шины FSB и внешней шины QPI в подобных системах.
Еще одним компонентом чипсета является функциональный контроллер ввода-вывода (от англ. I/O Controller Hub, ICH), так называемый южный мост, служащий для связи центрального процессора (через северный мост) с устройствами, не столь критичными к скорости взаимодействия:
Контроллеры PCI (X, E), прерываний, SMBus (I2C), LPC, IDE/SATA DMA, IRQ, ISA;
Super I/O: контроллер floppy-дисководов; контроллер LPT-порта; Контроллер COM-портов; MIDI, джойстик, инфракрасный порт и т.п.
Часы реального времени RTC (от англ. Real Time Clock);
BIOS (CMOS), вместе с энергонезависимыми системами обеспечения;
Системы энергообеспечения APM и ACPI;
Может включать в себя контроллеры Ethernet, USB, RAID, FireWire и т. п.
Особенностью южного моста является его взаимодействие с внешними устройствами. Как следствие, он довольно чувствителен различным негативным факторам, влияющим на нормальную работу устройств (короткое замыкание, перегрев, деформация материнской платы и т. п.). Замена южного моста, как правило, составляет стоимость самой материнской платы, поэтому замена его нерациональна из-за ее высокой стоимости и обычно не проводится.
Шина BSB (от англ. Back Side Bus) служит для соединения центрального процессора с кэш-памятью второго уровня для процессоров, в которых используется двойная независимая шина DIB (от англ. Dual Independent Bus), которая также называется вторичным (или внешним) КЭШем (и носит обозначение L2-cache).
Компанией Intel была разработана системная шина QPB (от англ. Quad Pumped Bus), передающая 4 64-разрядных блока данных или 2 адреса за такт, тогда как пытавшаяся получить лицензию на системную шину GTL+ для создания своих новых процессоров, компания AMD вынуждена была при создании процессоров серии К7 лицензировать шину EV6 для процессоров AMD Athlon и Athlon XP передающую данные два раза за такт (Double Data Rate).
Данная шина оказалась значительно сложнее в производстве, чем предыдущие исполнения. Данное обстоятельство не могло не сказаться на серьезном увеличении количества транзисторов, используемых для реализации вышеуказанного принципа передачи данных, как для процессора, так и для самого чипсета.
DMI (от англ. Direct Media Interface) – шина, которая была разработана компанией Intel, для соединения южного и северного мостов материнской платы. Для разъема LGA 1156 со встроенным контроллером памяти (продукты Core i3, Core i5 и некоторые серии Core i7 (800, к примеру)), DMI соединяет процессор и чипсет PCH (от англ. Platform Controller Hub) по технологии CtC (от англ. Chip-to-Chip).
PCH является, по сути, аналогом южного моста, однако представляет из себя совершенно новый P55 Ibex Peak. Фактически, в новом решении сочетается расширенный функционал предыдущих версий южных мостов компании Intel, а также дополнительный контроллер PCI-e для периферии.
Первыми чипсетами, построенными с помощью технологии DMI, были устройства серии Intel i915, на основе сокета LGA 1156, получившие свое распространение с 2004 года.
Пропускная способность DMI составляет 2 Гбайт/с. Из-за столь невысоких значений, инженеры Intel пошли на революционное решение, встроив контроллер памяти, PCI-e и непосредственно интерфейс DMI в сам процессор.
HyperTransport (ранее известная, как Lightning Data Transport) – технология последовательной/параллельной связи, разработанная с использованием технологии P2P (от англ. «point-to-point»), которая обеспечивает достаточно высокую скорость при низком уровне латентности (от англ. Low-latency responses), которая обеспечивает межпроцессорную связь, связь процессоров с сопроцессорами и процессоры с I/O Controller Hub. Имеет оригинальную схему на основе соединений, тоннелей, последовательного объединения нескольких тоннелей в цепь и мостов (для организации маршрутизации пакетов между цепями) для более простого масштабирования всей системы.
HyperTransport оптимизирует внутрисистемные связи заменой шин и мостов на их физическом уровне. Также тут используется DDR (от англ. Double Data Rate), что позволяет производить до 5.2×109 посылок в секунду с частотой синхронизации сигнала на уровне 2.6 гигагерц.
| Версия | Год | Максимальная частота (МГц) | Максимальная ширина (бит) | Пиковая пропускная способность (Гбайт/сек) |
| 1.0 | 2001 | 800 | 32 | 12.8 |
| 1.1 | 2002 | 800 | 32 | 12.8 |
| 2.0 | 2004 | 1400 | 32 | 22.4 |
| 3.0 | 2006 | 2600 | 32 | 41.6 |
| 3.1 | 2008 | 3200 | 32 | 51.6 |
Очередной шаг в совершенствовании научно-технического процесса был обозначен инженерами компании Intel созданием нового типа системной шины QPI (от англ. Quick Path Interconnect, ранее известной, как Common-System Interface, или CSI). Она заключается в интегрированном контроллере памяти и быстрой последовательной шины P2P для доступа к распределенной и разделяемой памяти.
Необходимость повышения скорости обработки и обмена данными диктует более жесткие требования к пропускной способности шины. С развитием технологии и характеристик процессоров нового поколения, использование FSB уже неактуально и в полной мере является наглядным изображением пресловутого эффекта «бутылочного горлышка». Результатом модернизации технологии FSB было создание шины нового поколения – QPI. Общая пропускная способность данного нового вида системной шины достигает невероятных (для предшественников) значений в 25.6 ГБ/с.
Первые процессоры, построенные на технологии использования системной шины QPI, поступили на рынок в начале 2008 года. Данная технология является прямым конкурентом консорциума, во главе с компанией AMD, выпустившей системную шину HyperTransport.
Название микроструктуры процессорного ряда компании Intel — Nehalem произошло от названия небольшого города в США неподалеку от головного офиса компании Intel в г. Санта-Клара (основанного в 18 веке) в Калифорнии. Nehalem является продолжением процесса модернизации модельного ряда архитектур Intel x86. Свое продолжение в 2010 году QPI получила в процессоре серии Itanium 9300, получив кодовое имя Tukwila, что является большим шагом вперед для систем, построенных на базе Itanium. Вместе с QuickPath в процессоре используется встроенный контроллер памяти, и интерфейс памяти прямо использует интерфейс QPI для взаимодействия с другими процессорами и I/OCH. Именно в этих продуктах наиболее типичным решением и стала системная шина QPI, что делает вероятной возможность использования одного чипсета процессорами Tukwila и Nehalem.
Каждое ядро процессора содержит интегрированный контроллер памяти и скоростное соединение для подключения иных компонентов. Данная структура служит для обеспечения следующих аспектов:
Огромной производительности и удобства работы с памятью;
Динамически изменяемой полосы эффективного пропускания при связи процессора с иными компонентами системы;
Значительного увеличения характеристик RAS (от англ. Reliability, Availability, Serviceability, что дословно означает «надежность, доступность и обслуживаемость») — достигается для достижения наилучшего баланса между ценой, производительностью и энергоэффективностью.
Чипсеты с разъемом LGA 1366 используют шину DMI для связи между северным мостом и южным мостом. А процессоры для сокета LGA 1156 вообще не имеют внешнего интерфейса QuickPath, т.к. чипсеты для данного сокета взаимодействуют с однопроцессорными конфигурациями, а функционал северного моста же напрямую встроен в сам процессор, что заставляет использовать шину DMI для связи процессора с аналогом южного моста. Однако, встроенная шина QPI используется в процессорах сокета LGA 1156 для связи ядер и встроенного контроллера PCI-e внутри самого процессора.
Данные, передаваемые в виде датаграмм (пакетов) в системной шине QPI передаются по паре односторонних каналов, каждый из которых состоит из 20 пар проводов. Общая ширина канала составляет 20 бит, при этом 16 бит служат для передачи исключительно данных (полезной нагрузки). Максимальная пропускная способность одного канала варьируется от 4.8^109 до 6.4^109 транзакций в секунду, следовательно, общая максимальная пропускная способность одного соединения приближается к значениям от 19.2 до 25.6 ГБ/с в двух направлениях, что составляет, соответственно, от 9.6 до 12.8 ГБ/с в каждую сторону.
В настоящее время системную шину QPI используют, в основном, для серверных решений. Связано это обстоятельство с тем, что QPI приобретает максимальную эффективность (и КПД) именно в загруженности пересылкой данных в оба направления, как в случае с многосокетными рабочими станциями или, собственно, серверами.
Как показывают тесты, для пользовательских машин использовать решения на основе QPI нецелесообразно, так как даже намеренное снижение пропускной способности QPI в 2 раза никоим образом не влияет на получаемые результаты в тестах, даже при условии использования связки из 3 наиболее производительных графических адаптеров.
PCI (от англ. Peripheral Component Interconnect bus) – шина для соединения материнской платы с периферийными устройствами различного рода.
Начало PCI было положено в начале 1992 года компанией Intel (для замены шины VLB (от англ. Vesa Local Bus)), которая допустила полноценное использование возможностей процессоров 486, Pentium и Pentium Pro, при этом стандарт шины с самого начала был открыт, что гарантировало возможность создания устройств для шины PCI без обязательства лицензирования.
В 1993 году в ходе маркетинговой политики по продвижению PCI на рынке вышла PCI 2.0. В 1995 году данная модель модифицировалась до версии PCI 2.1.
PCI имела реальную тактовую частоту на уровне 33 МГц, тактовой частотой для версии 2.1 стало значение в 66 МГц, что позволило повысить скорость передачи данных до 533 Мбайт/с. Вместе с тем, и в операционных системах (Windows 95, к примеру) уже была предусмотрена поддержка шины PCI 2.1, которая стала настолько популярной, что вскоре была использована при создании платформ процессоров Alpha, MIPS, PowerPC, SPARC и т.д.
Однако, ничего не стоит на месте, включая научно-технический процесс, поэтому в связи с разработкой шины PCI Express, AGP и PCI практически не используются в решениях высшего ценового диапазона.
PCI Express получила свое кодовое название 3GIO (от англ. 3rd Generation I/O) – компьютерная шина, использующая последовательную передачу данных, обеспечиваемую высокопроизводительным физическим протоколом на основе программной модели шины PCI.
В связи с тем, что использование параллельной передачи данных, при попытке увеличить производительность, будет означать физическое ее расширение, последовательная передача данных обладает возможностью масштабирования (1x, 2x, 4x, 8x, 16x и 32x) а, значит, более приоритетна в разработке. Топология PCI Express, в общем случае, представляет собой звезду со взаимодействием между собой устройств через среду, образованную коммутаторами, с прямой связью каждого устройства соединением P2P.
Очередными отличительными особенностями PCI Express являются:
Возможность горячей замены карт;
Возможность создания виртуальных каналов, гарантирования полосы пропускания и количество времени отклика, а также сбора статистики QoS (от англ. Quality of Service)
Возможность влиять на энергопотребление оборудования ASMP (от англ. Active State Power Management) – перевод устройства в режим уменьшенного энергопотребления в случае его простоя в течение конкретного (задаваемого программно) интервала времени;
Контроль целостности информации и структуры данных, предназначенных для передачи – алгоритм Data Link прикрепляет к пакету данных (в передаче) контрольную сумму последовательности и ее номер, что позволяет обнаруживать все одиночные и двойные ошибки, а также ошибки в нечетном числе бит – CRC (от англ. Cyclic Redundancy Check).
В отличие от PCI (использование подключения к общей 32-разрядной параллельной двунаправленной шине), PCI Express использует двунаправленное последовательной соединение P2P, а соединение между двумя устройствами состоит из 1 (2, 4, 8, 16, 32) двунаправленных линий. На электрическом уровне каждое соединение способно подключаться к PCI Express всего лишь 4 проводниками.
Преимущества подобного решения налицо:
Устройство корректно работает в таком же слоте, или большей пропускной способности;
Корректная работа слота возможна даже при использовании не всех линий (однако в таком случае необходимо подключение и заземление всех проводников питания);
Физическая составляющая слота не позволит допустить некорректную работу системы, в случае попытки вставить устройство в слот с меньшей пропускной способностью, дифференциацией размеров слотов x1 (x2, x4, x8, x16, x32).
Чтобы высчитать пропускную способность PCI Express, нужно учесть битрейт, дуплексность связи и процент (отношение) эффективного количества «полезной нагрузки» бит к общему количеству (в PCI Express 1.0 и 2.x это отношение выглядело, как 8 бит информации / 10 бит служебных данных). Перемножая все три значения, получим скорость передачи данных. Так общая пропускная способность шины PCI Express 3.0 достигает 1 Гбайт/с для каждой линии при сигнальной скорости передачи данных в 8 GT/s (для 2.0 этот показатель был равен 5 GT/s, а для 1.0 – вообще 2.5 GT/s). А для планируемого к стандартизации и спецификации к 2014-2015 гг. стандарта 4.0 планируется удвоить показатель сигнальной скорости до 16 GT/s или даже более, что будет, по-меньшей мере, в 2 раза быстрее PCI Express 3.0
В настоящее время развитие технологий дает потребителям возможность выбирать технологию себе по вкусу из огромного количества вариантов. Решение различного рода задач потребителей задает необходимость определяться с наилучшим соотношением «цена-качество-целесообразность». К примеру: обыватель не замечает разницы в производительности между системами, построенных на базе сокета LGA 1366 (используется системная шина QPI) и сокета LGA 1156(1155) (используется системная шина DMI) в силу достаточности технологии, связанной с LGA 1156 и отсутствием задач, для которых ресурс данной системы был бы недостаточен. Лишь настоящие ценители и коллекционеры не откажут себе в радости приобретения компьютера, ресурс которого не будет использован и на 50%. Для потребителей-корпораций и крупных фирм нередко уже недостаточно производительности шины DMI.
Разрыв в разнице задач растет соответственно уровню потребителя. Кто знает, какие технологии используются в суперкомпьютерах мировых держав, однако ясно одно: именно эти технологии мы и будем использовать в ближайшем будущем.
- Свежие записи
- Нужно ли менять пружины при замене амортизаторов
- Скрипят амортизаторы на машине что делать
- Из чего состоит стойка амортизатора передняя
- Чем стянуть пружину амортизатора без стяжек
- Для чего нужны амортизаторы в автомобиле